

Por onde se aprofundar em IA: matemática, estatística e ML
O outro extremo do "por onde começar com IA": matemática, estatística e machine learning em 54 notebooks abertos, pra quem escreve código.

Oi, bom tê-los de novo por aqui.
Há algumas semanas eu publiquei o Por onde eu começo?, contando da academia-ia, a trilha gratuita de 30 dias pra quem sempre se prometeu entender IA e nunca passou do módulo três de curso nenhum. No meio daquele texto, quase como nota de rodapé, eu deixei um aviso:
“Se você é engenheiro de ML procurando matemática de transformer, esse curso não é pra você.”
Eu escrevi aquela frase pra fechar uma porta. Hoje eu volto pra abrir a outra. Porque a pergunta do jantar de família tem uma irmã menos famosa, que chega por canais diferentes e com outro sotaque. Esse texto é pra ela.
A outra cena
Ela não aparece no jantar de família. Aparece no Slack do trabalho, no grupo de devs, na conversa que sobra depois da daily. E quase sempre vem numa versão de:
“Cara, eu uso essas APIs todo dia. Já fiz fine-tuning seguindo tutorial, já subi RAG em produção. Mas se você me perguntar por que o Adam converge onde o SGD patina, eu não sei. Eu copio. A IA faz pra mim… Por onde eu me aprofundo?”
Quem pergunta isso não é iniciante. É dev, é engenheiro de dados, é cientista de dados formado em bootcamp, é o Pleno que virou “a pessoa de IA” da empresa por ter chegado primeiro. Essa pessoa constrói coisas que funcionam. E é exatamente por isso que a sensação incomoda tanto: o chão funciona, mas soa oco quando você bate.
Os sintomas são sempre os mesmos. Você chama model.fit() e não sabe dizer o que acontece entre a primeira época e a segunda. Você ajusta learning_rate por superstição, não por diagnóstico. Você abre um paper, atravessa o abstract com confiança e afunda na equação dois. Você sabe que normalizar os dados melhora o treino, mas não por quê, então quando não melhora você não tem pra onde ir. E a cada tutorial novo a sensação se repete: você terminou, funcionou, e você sabe um pouquinho menos do que parece.
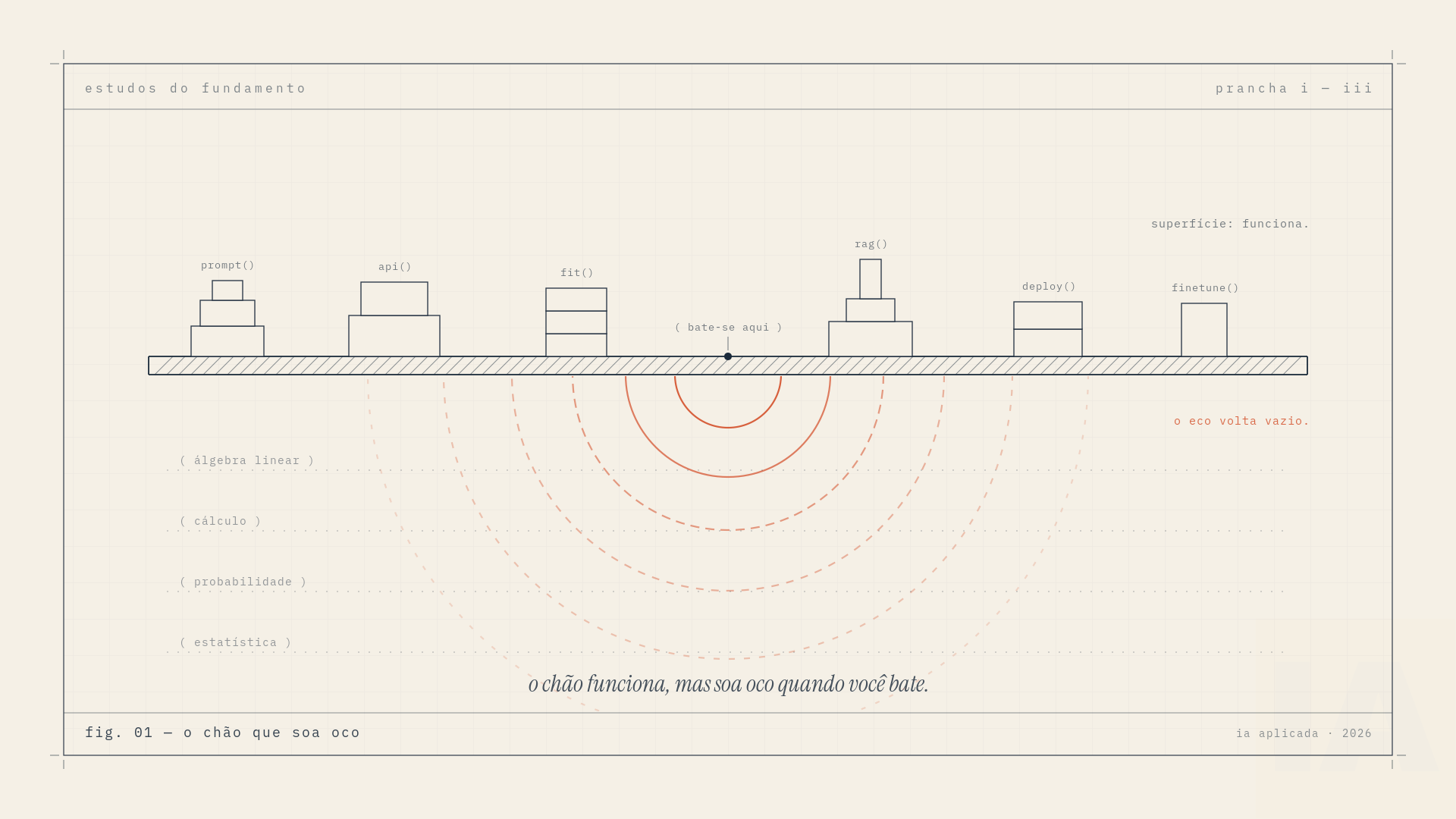
Isso tem nome, e você provavelmente já se ouviu dizendo: tutorial hell. O inferno não é a falta de material. É o excesso de material que te ensina a fazer sem nunca te cobrar entender.
O que existe lá fora, de novo, não resolve
Quando essa pergunta começou a chegar, eu fiz o mesmo exercício do texto anterior: sentei pra recomendar um caminho e percebi que não tinha um inteiro pra recomendar.
Os cursos de “ML na prática” ensinam receita de framework. Você sai sabendo qual função chamar e em que ordem, que é exatamente o conhecimento que evapora a cada major release. A matemática, quando aparece, vem num slide de 40 segundos com a promessa de que “você não precisa entender isso agora”. Spoiler: o agora chega.
Os livros bons existem e são ótimos. Mas livro de matemática é passivo. Você lê a derivação do gradiente, acena com a cabeça, vira a página, e três dias depois não reconstrói nem a primeira linha. Entender de verdade exige fazer, errar, plotar, comparar com a implementação de referência. Papel não roda código.
Os papers assumem a base que você está tentando construir. Ler paper sem álgebra linear e probabilidade sólidas é decifrar um idioma com dicionário rasgado. Dá pra fingir por um tempo, todo mundo finge por um tempo, mas fingir cansa.
E tem o filtro que quase ninguém nomeia: quase nada disso existe em português. O material de profundidade real está em inglês, o que cria um pedágio duplo. A pessoa paga pra entender o conceito difícil e paga de novo pra entender a língua em que o conceito difícil foi escrito. Tem muita gente boa ficando na superfície não por falta de capacidade, mas por excesso de pedágio.
A conclusão foi a mesma da outra vez, com o sinal trocado: ninguém precisa de mais um tutorial de “construa seu chatbot em 15 minutos”. Precisa de um caminho. Só que dessa vez um caminho longo, com equação, com código e com exercício que não aceita cola.
O que eu construí
Chama math-statistics-for-ai. É um repositório público no GitHub: github.com/guifav/math-statistics-for-ai.
São 54 notebooks Jupyter executáveis, somando 2.596 células, sendo 1.672 de texto e 924 de código. Tudo em português. Licença MIT, que é o jeito jurídico de dizer “isso é seu também”.
Cada notebook é uma aula completa: cabeçalho com pré-requisitos mapeados, tempo estimado, fio narrativo explícito, teoria intercalada com código que roda, exercícios marcados como TAREFA DO ALUNO e soluções executáveis em células com tag solution, separadas de propósito pra você suar antes de espiar. No final, seção de erros comuns e conexões com o que vem depois. Tem até validador automático rodando em CI, que checa sintaxe, referências internas e metadados de cada notebook a cada push, porque material de estudo com célula quebrada é desrespeito com quem estuda.
A filosofia é uma só: nenhum conceito entra sem os três estados. A equação, o código e o caso de uso. Se você só viu a equação, você não aprendeu. Se você só rodou o código, também não.
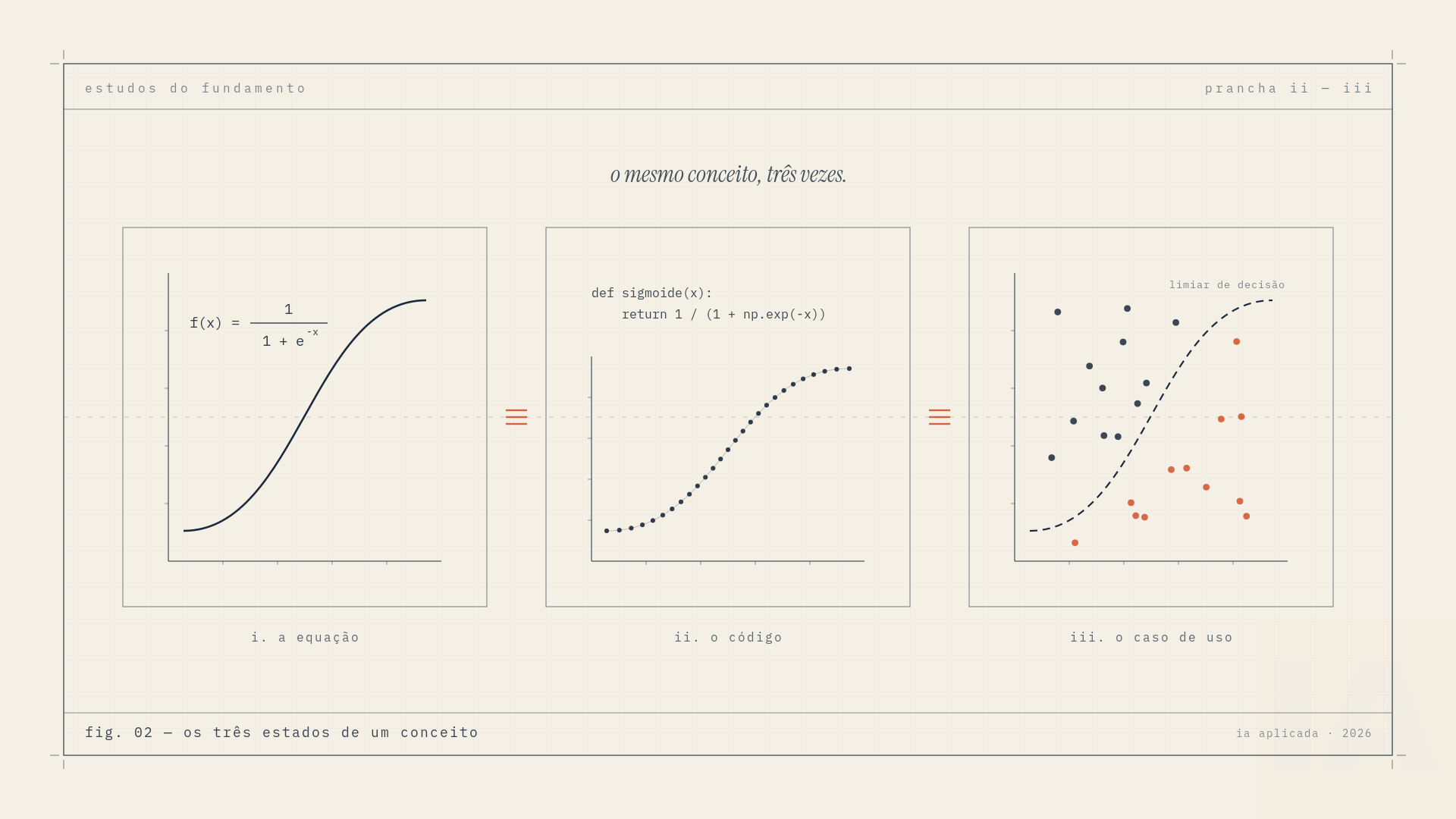
O caminho
São sete módulos, do zero matemático até o modelo rodando em produção. Não precisa percorrer linearmente, cada notebook declara seus pré-requisitos, mas a ordem existe por um motivo.
Módulo 00, Matemática, 8 notebooks. A fundação que todo mundo pula e depois paga juros. Começa em pré-cálculo, funções, exponenciais e logaritmos, exatamente as que viram funções de ativação. Passa por álgebra linear em duas camadas: vetores, produto interno, normas e similaridade, que é literalmente a matemática por trás de embeddings e busca vetorial; depois matrizes, transformações, autovalores, PCA e SVD. Segue pra cálculo: derivadas, gradientes, Jacobiano, Hessiano, até você implementar backpropagation entendendo cada passo; depois integrais, séries, Monte Carlo e a razão de a área sob a curva ROC se chamar área. Fecha com probabilidade em dois níveis, de Bayes e distribuições até MLE, inferência bayesiana e GMM, e com otimização: convexidade, SGD, Momentum, RMSprop, Adam e por que regularização funciona em vez de apenas “usar L2”. Pra calibrar expectativa: só o notebook de derivadas estima 10 a 12 horas de estudo. E vale cada uma, porque é ali que loss.backward() deixa de ser mágica.
Módulo 01, Estatística, 5 notebooks. O que separa quem treina modelo de quem confia em modelo. Descritiva e visualização, inferência com intervalos de confiança, testes de hipótese, ANOVA, bootstrap e o problema dos múltiplos testes, que é onde a maioria dos dashboards mente. Estatística bayesiana de verdade, priors, posteriors, e a revelação de que MAP e regularização são a mesma ideia com roupas diferentes. Regressão como estatístico vê, com diagnóstico de resíduos e multicolinearidade. E design de experimentos: poder estatístico, A/B testing, causalidade, DAGs e validação temporal. Se você já lançou uma feature baseada num teste A/B mal desenhado, esse módulo vai doer de um jeito produtivo.
Módulo 02, Data Science, 4 notebooks. O menos glamouroso e o que mais paga aluguel. NumPy e Pandas a sério, EDA com framework em vez de improviso, missing values, outliers e leakage, que é o bug silencioso que infla métrica e destrói credibilidade. SQL com joins e window functions, APIs com paginação e retry, e acesso a dados de gente grande: PostgreSQL, ORM, Parquet, feature stores e segurança.
Módulo 03, Machine Learning, 7 notebooks. Os clássicos, sem pressa. Classificação completa com as métricas que importam e quando cada uma mente, regressão com regularização, árvores e ensembles, bagging, Random Forest e boosting com seus trade-offs, SVM e o kernel trick, clustering com K-Means, DBSCAN e GMM, redução de dimensionalidade com PCA, t-SNE e UMAP e como não se enganar com elas. E um tutorial from-scratch que percorre o fluxo inteiro, dos dados crus à avaliação. Pular os clássicos pra ir direto pra LLM é construir o décimo andar primeiro.
Módulo 04, Deep Learning, 6 notebooks. Fundamentos de redes neurais, arquiteturas, e treinamento na vida real, o que fazer quando o loss não desce, que é o dia a dia que nenhum tutorial mostra. Transfer learning, e dois notebooks que quase nunca aparecem em curso: aceleração de hardware e otimização de Python. É a parte em que entender a máquina vira dinheiro, seu ou da empresa.
Módulo 05, Domínios Aplicados, 20 notebooks em 4 submódulos. Visão computacional: CNNs por dentro, convolução, pooling e receptive field, classificação com augmentation e interpretabilidade, detecção com IoU, NMS, YOLO e R-CNN, segmentação com U-Net, e Vision Transformers até modelos vision-language. NLP, a trilha completa: do TF-IDF e n-grams a Word2Vec, RNNs e LSTMs, self-attention, BERT e fine-tuning, LLMs com scaling laws, prompting e alinhamento, e fechando com RAG, um dos maiores notebooks do repositório, 83 células cobrindo chunking, embeddings, busca vetorial, retrieval e avaliação. Se você já subiu RAG copiando arquitetura de blog post, esse notebook explica o sistema que você opera. IA generativa: GANs, VAEs com ELBO e espaço latente, diffusion models em 94 células, fine-tuning com LoRA e adapters, e multimodal. E séries temporais: estacionariedade, ACF e PACF, ARIMA e Prophet, ML com lag features e validação temporal, e deep learning sequencial até Transformers.
Módulo 06, MLOps, 4 notebooks. Porque modelo que não chega em produção é PDF caro. Deploy com API, contratos e versionamento, MLflow pra parar de rastrear experimento em planilha, monitoramento e drift com PSI e KS test, e pipelines com CI/CD, DVC e feature stores.
Como estudar isso sem se enganar
Aqui vai a parte honesta, e ela é o espelho invertido do texto anterior.
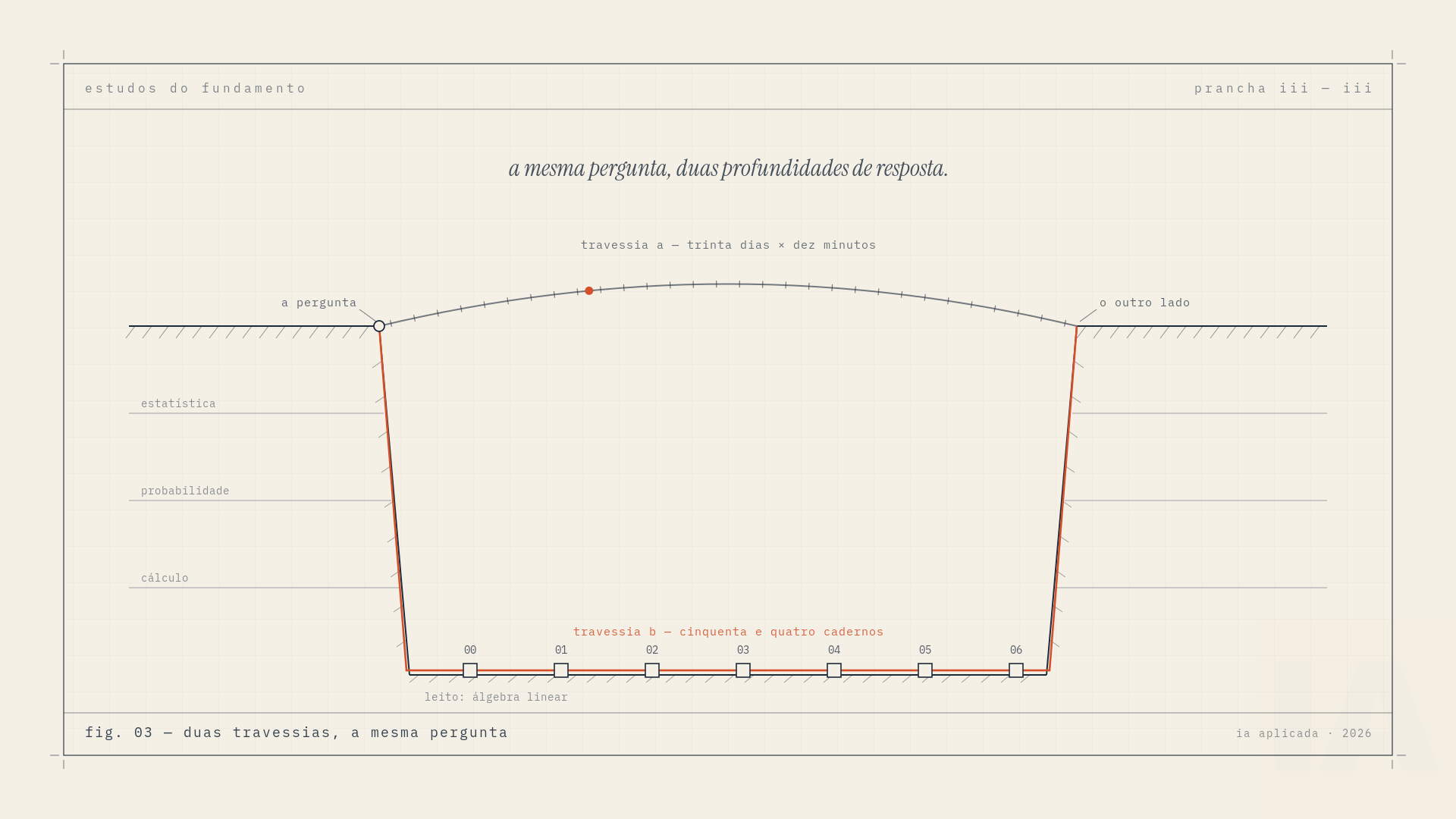
A academia-ia cabe em 10 minutos por dia porque foi desenhada pra caber. Esse repositório não cabe. Isso aqui é material de meses, na escala de centenas de horas se você fizer direito. Não existe versão comprimida de profundidade, e qualquer pessoa que te vender uma está te vendendo a sensação, não a coisa.
O que existe é método:
Rode tudo. Notebook não é PDF. Se você leu sem executar, você não passou por ali.
Quebre o código de propósito. Mude o hiperparâmetro pro valor errado, tire a normalização, veja o treino degradar. Intuição se constrói no contraste.
Faça a
TAREFA DO ALUNOantes de abrir a solução. As soluções estão lá, executáveis, marcadas com tag. A distância entre olhar a resposta e produzir a resposta é exatamente a distância que você está tentando atravessar.Use os pré-requisitos como grafo, não como burocracia. Cada notebook declara o que assume. Se a equação dois te afundar, o cabeçalho diz pra onde voltar.
Não estude em ordem de hype. A vontade de pular pro notebook de LLM é compreensível. Mas ele rende o dobro pra quem chegou nele por dentro do caminho.
Setup em quatro linhas: clone, venv, pip install -r requirements.txt (ou requirements-gpu.txt se você tem CUDA 12.1), jupyter lab notebooks. Tem validação leve pra quem quer checar a integridade sem instalar o stack científico inteiro.
Por que aberto, e por que em português
Quem leu o texto anterior já conhece a frase da minha mãe, faça o seu melhor sem esperar nada em troca, então não vou repetir o argumento inteiro. Vou só estender ele um degrau.
Lá eu escrevi que IA não pode ser privilégio. Profundidade também não. Existe uma versão dessa exclusão que é mais sutil que o preço do curso: é a exclusão por idioma e por fragmentação. O conhecimento de base está disponível, tecnicamente, mas espalhado em inglês por dezenas de fontes que não conversam entre si. Juntar tudo, ordenar, traduzir pra nossa língua e abrir o código é o tipo de coisa que precisava existir e não existia.
Então é MIT. Sem cadastro, sem paywall, sem versão premium. E como é um repositório e não um produto, ele tem uma vantagem que curso nenhum tem: aceita pull request. Achou erro, abre issue. Quer melhorar um notebook ou propor um novo, o CONTRIBUTING.md explica o rito e o validador garante que nada entre quebrado. Material de estudo aberto fica melhor do jeito que software aberto fica melhor: em público, um commit por vez.
Os dois extremos da mesma pergunta
Agora as duas portas estão abertas.
Se você, ou alguém que você conhece, está no ponto de partida, sabe que IA importa mas não sabe nem o que perguntar, o caminho é a academia-ia: 30 dias, 10 minutos por dia, do zero ao uso consciente. O texto sobre ela está aqui.
Se você é a pessoa técnica que já constrói com IA mas decidiu que cansou de copiar, o caminho é o math-statistics-for-ai: 54 notebooks, da inclinação da reta ao drift em produção, no seu ritmo, pra sempre.
É a mesma pergunta nos dois casos. Por onde eu começo? Só muda a profundidade da resposta que você está pronto pra receber.
Bora?
O repositório está no ar: github.com/guifav/math-statistics-for-ai.
Clona, abre o módulo 00 e roda a primeira célula hoje. Não o módulo que parece mais interessante, o 00 mesmo, e seja honesto consigo na avaliação: se for fácil, você acelera sem perder nada; se não for, você acabou de descobrir onde o chão estava oco.
Estrela no repositório é vaidade, eu prefiro issue. Se você travar em algum notebook, achar um erro ou tiver uma sugestão, abre uma issue que eu leio, do mesmo jeito que leio as respostas desta newsletter.
E se você conhece alguém preso no tutorial hell, e você conhece, todo time tem pelo menos um, manda esse texto. A ponte pro outro lado continua aberta, só que dessa vez ela é mais longa, e a vista lá de cima compensa cada hora da travessia.
Obrigado por estar por aqui, como sempre.
Abs,
Guilherme
PS: se você chegou até aqui e percebeu que esse texto não é pra você, que as equações te assustam e você só queria entender essa tal de IA, sem drama nenhum: o texto pra você é o anterior, e a academia-ia te espera com 10 minutos por dia. As duas portas levam pro mesmo lugar.