

Self-Improvement Architecture: um padrão para aplicações que aprendem com uso real
A maioria das aplicações recebe feedback dos usuários e não faz nada com ele. Este padrão fecha essa lacuna com agentes, guardrails e humano no loop onde importa.

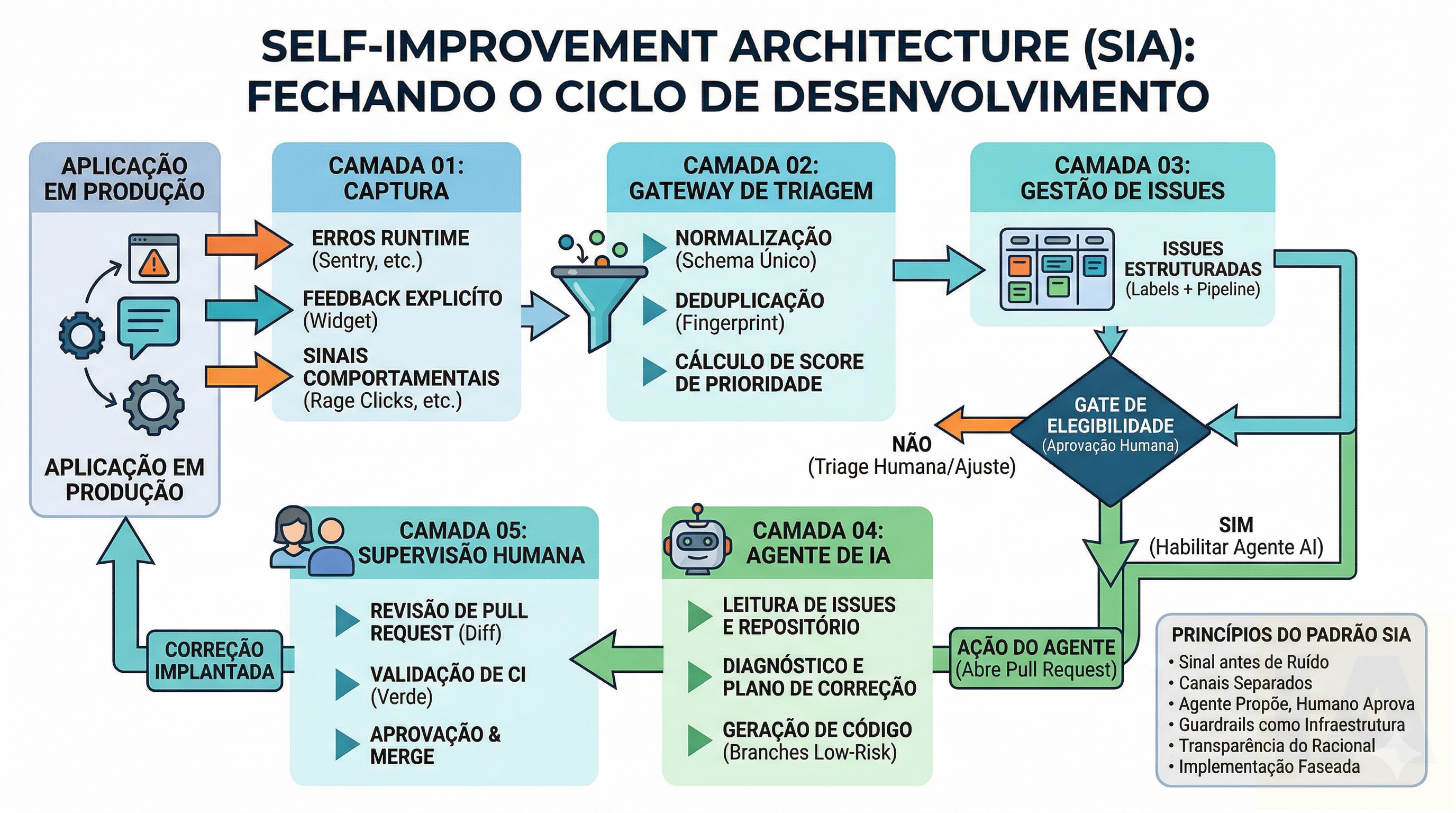
Existe uma lacuna estrutural entre o momento em que um usuário encontra um problema em uma aplicação e o momento em que esse problema é corrigido. Essa lacuna tem nome: ela se chama processo manual de reporte, triagem e priorização. E em praticamente todas as equipes de produto que conheço, ela é grande o suficiente para que boa parte dos problemas nunca chegue a ser resolvida.
O volume de sinais cresce mais rápido do que a capacidade de processá-los com atenção: erros de runtime, feedback qualitativo, solicitações de melhoria, tickets do suporte. O resultado é um backlog que se torna cemitério.
A Self-Improvement Architecture é um padrão de design de sistemas que propõe fechar essa lacuna com automação inteligente e agentes de IA. A forma assistida: máquinas fazem o trabalho de baixo valor cognitivo e humanos concentram sua atenção onde ela é insubstituível.
Self-Improvement Architecture (SIA) é um conjunto de camadas de software que captura sinais de qualidade de uma aplicação em produção, normaliza e prioriza esses sinais automaticamente, e alimenta um agente de IA capaz de diagnosticar problemas e propor correções no próprio código-fonte da aplicação, com supervisão humana nos pontos críticos.
Diferente de práticas convencionais de monitoramento e gestão de defeitos, a SIA fecha o loop inteiramente dentro do ciclo de desenvolvimento: da observação em produção até o pull request, passando por triagem, diagnóstico e geração de código.
Por que o momento é agora
A conversa sobre agentes de IA gerando código existe há algum tempo. O que mudou recentemente é a maturidade dos componentes que tornam um sistema assim viável em produção: ferramentas de observabilidade que capturam contexto rico de sessão, modelos de linguagem com janelas de contexto grandes o suficiente para processar arquivos de código real, e infraestruturas de agentes que permitem controle granular sobre o que o sistema pode e não pode fazer.
A pergunta central também mudou. Saiu de “é tecnicamente possível?” e passou a ser “como fazer isso de forma que o benefício supere consistentemente o risco?”. É essa pergunta que o padrão SIA tenta responder.
“Um agente que age sem critério vira fábrica de tickets. Um agente com critério vira alavanca de produtividade.”
As cinco camadas do padrão
A SIA é organizada em camadas independentes. Cada uma pode ser implementada separadamente, e a ordem importa: cada camada só gera valor se a anterior estiver funcionando bem.
Camada 01 — Captura
Instrumentação da aplicação para coletar três tipos de sinal: erros de runtime com contexto de sessão, feedback explícito do usuário via widget integrado, e sinais comportamentais passivos como rage clicks, abandono de fluxo e endpoints lentos. Esses canais são deliberadamente separados, porque cada tipo de sinal tem critérios diferentes de triagem.
Camada 02 — Normalização e Triagem
Um serviço intermediário recebe todos os sinais e os converte para um schema único. Aqui acontecem deduplicação por fingerprint, enriquecimento com dados de contexto e cálculo de score de prioridade. Nenhum sinal chega ao repositório antes de passar por essa camada. É o filtro que impede o backlog tóxico.
Camada 03 — Gestão de Issues
O sistema de controle de versão funciona como hub de execução técnica. Issues chegam já estruturadas com contexto, evidências e score. Um sistema de labels e pipeline de projeto torna o estado de cada problema visível sem esforço humano de atualização manual.
Camada 04 — Agente
O agente de IA entra em cena somente após a camada anterior. Ele lê issues que atingiram um gate explícito de elegibilidade, produz diagnóstico, identifica arquivos afetados no repositório e, para problemas de baixo risco com critérios definidos, abre um pull request em branch separada com o racional completo documentado.
Camada 05 — Humana
O humano é posicionado onde sua atenção tem maior valor: decidindo o que priorizar, aplicando o gate de elegibilidade para o agente e revisando pull requests antes do merge. Merge automático e ação do agente em áreas sensíveis sem aprovação explícita estão fora do escopo do padrão.
O fluxo completo
[ APLICAÇÃO ]
├── erros runtime
├── feedback explícito
└── sinais comportamentais
│
▼
[ GATEWAY ] ── normaliza, deduplica, pontua
│
▼
[ ISSUES ] ── estruturadas + labels + pipeline
│
gate: ai-ready?
├── NÃO ──▶ [ HUMANO ] decide: prioriza / descarta
└── SIM ──▶ [ AGENTE ] diagnostica + plano
│
risco low?
├── NÃO ──▶ [ HUMANO ] decide
└── SIM ──▶ [ PR ] branch separada
│
▼
[ HUMANO ] revisa + aprova + mergeO gate de elegibilidade — a peça mais importante
A diferença entre um sistema de self-improvement que funciona e um que degenera em caos está quase inteiramente no gate de elegibilidade para ação autônoma do agente.
A lógica é simples: o agente age sozinho apenas quando três condições são satisfeitas simultaneamente. O problema é bem delimitado: stack trace claro, módulo identificável, reprodução documentada. A mudança é de baixo risco: sem tocar regras de negócio, autenticação, dados financeiros, migrações destrutivas ou arquitetura. E um humano aplicou explicitamente a label de elegibilidade após revisar o diagnóstico inicial.
O gate existe porque alguns tipos de problema requerem julgamento contextual que exige atenção humana deliberada.
O agente pode agir sozinho quando:
Bug com stack trace claro e reproduzível
Correção de texto ou label na UI
Validação de campo ausente ou incorreta
Tratamento de erro faltando
Tipagem incorreta ou ausente
Teste unitário faltando para função isolada
Refactor localizado sem mudança de comportamento
O humano é obrigatório quando:
Mudança de regra de negócio ou lógica de domínio
Qualquer coisa relacionada a auth ou permissões
Cobrança, faturamento, dados financeiros
Migration destrutiva de banco de dados
Mudança de arquitetura ou dependência principal
Issues sem reproduzibilidade mínima documentada
O gate precisa ser definido por escrito, versionado e revisado periodicamente. À medida que o sistema ganha histórico, você terá dados reais sobre a taxa de assertividade do agente e poderá expandir ou contrair os critérios com base em evidência.
Os seis princípios do padrão

1. Sinal antes de ruído
Nenhum evento deve virar issue diretamente. Todo sinal passa por normalização, deduplicação e scoring antes de qualquer criação de ticket. Um sistema de self-improvement mal configurado gera backlog mais rápido do que resolve problemas.
2. Canais separados, critérios separados
Erro de runtime e solicitação de feature são animais diferentes. O fluxo de triagem, os critérios de priorização e as expectativas de resposta são distintos para cada tipo. Misturá-los é uma das causas mais comuns de falha em sistemas desse tipo.
3. O agente propõe, o humano aprova
Mesmo nos casos de baixo risco onde o agente abre PR, o merge é sempre humano. A arquitetura correta para construir confiança progressiva no sistema é essa: autonomia restrita no início, expandida gradualmente com base em dados reais de assertividade.
4. Guardrails como infraestrutura, não como regras
Branch protection, CODEOWNERS, CI obrigatória e limites de permissão do agente devem ser configurados como infraestrutura técnica, não como política documentada. Os limites precisam existir na camada de execução, porque um agente com permissão para fazer algo eventualmente tentará fazê-lo.
5. Transparência do racional
Todo PR aberto pelo agente deve documentar: o problema identificado, os arquivos afetados, a solução escolhida, alternativas descartadas e o nível de confiança. Um PR sem racional documentado não deve ser mergeado.
6. Implementação faseada
A SIA cresce em etapas. A fase 1 entrega valor imediato com risco baixo: captura estruturada, triagem e diagnóstico sem autonomia de PR. As fases seguintes expandem autonomia gradualmente, baseadas em métricas reais de qualidade do sistema.
Fases de implementação recomendadas

Fase 1 — Captura + Triagem
Instrumentar a aplicação com ferramenta de observabilidade. Implementar widget de feedback com contexto da rota atual. Construir o gateway de normalização. Configurar templates de issue e taxonomia de labels. O agente apenas comenta diagnóstico, sem abrir PRs. Esta fase já entrega valor significativo e valida o modelo.
Fase 2 — Agente Semi-Autônomo
Definir e documentar os critérios do gate de elegibilidade. Habilitar o agente a abrir PRs em issues low-risk + ai-ready. Configurar branch protection, CODEOWNERS e CI obrigatória. Todo PR revisado e aprovado por humano antes do merge. Começar a coletar métricas de assertividade.
Fase 3 — Loop Completo
Deduplicação madura com clustering de feedback similar. Identificação proativa de padrões recorrentes. Analytics de tempo até correção, taxa de reabertura e assertividade do agente por tipo de problema. Expansão criteriosa dos critérios do gate com base nos dados acumulados.
Um ciclo completo na prática
Para tornar o padrão concreto, vale acompanhar um único problema do começo ao fim, com as ferramentas reais em cada etapa.
Cenário: um usuário tenta exportar um relatório em PDF dentro da aplicação. O botão não responde. Ele tenta três vezes e desiste.
Etapa 1 — O Sentry captura o erro
O SDK do Sentry, instalado na aplicação, registra automaticamente a exceção lançada pelo componente de exportação. O evento chega ao Sentry com stack trace completo, identificador da sessão, versão do release, navegador e a URL exata onde ocorreu. O Sentry também grava um Session Replay dos últimos 60 segundos de navegação do usuário.
Neste ponto, o erro existe no Sentry. O repositório ainda não sabe que ele aconteceu.
Etapa 2 — O gateway recebe o evento e decide
O Sentry dispara um webhook para o gateway (neste caso, um workflow no n8n). O gateway executa três verificações antes de qualquer ação:
Deduplicação: já existe uma issue aberta com o mesmo fingerprint? Se sim, incrementa o contador e atualiza a última ocorrência. Se não, continua.
Limiar: este erro atingiu o threshold de criação? O threshold configurado é 5 ocorrências em 24 horas ou 2 usuários únicos afetados. O erro aconteceu com 3 usuários em 4 horas. Passa.
Scoring: o gateway calcula o score combinando severidade (o botão de exportação é rota crítica), frequência (3 ocorrências em 4 horas) e confiança de diagnóstico (stack trace presente, módulo identificado). Score resultante: 74 de 100.
O gateway monta o payload da issue com todos os dados coletados e chama a GitHub Issues API.
Etapa 3 — A issue é criada no GitHub com contexto completo
A issue abre automaticamente com o template padronizado preenchido:
Título: [bug] Exportação de PDF falha silenciosamente em /reports/export
Contexto: source:sentry | route:/reports/export | release:v2.4.1 | browser:Chrome 122
Sintoma: TypeError: Cannot read properties of undefined (reading 'generate')
em ExportButton.tsx linha 47
Evidência:
- Stack trace completo: [link]
- Session Replay: [link Sentry]
- Ocorrências: 3 | Usuários afetados: 3 | Janela: 4h
Impacto: rota crítica de exportação | score: 74
Labels aplicadas automaticamente:
source:sentry | type:bug | priority:p1 | status:triage-needed | risk:low | module:reportsO GitHub Projects move a issue automaticamente para a coluna Needs Triage.
Etapa 4 — O agente faz a triagem
Um GitHub Actions workflow dispara ao detectar a label status:triage-needed. Ele chama o agente (Claude via API) passando o conteúdo completo da issue, o stack trace e os arquivos relevantes do repositório lidos via GitHub API.
O agente responde com um comentário na issue:
Diagnóstico: o método `generate()` está sendo chamado sobre o objeto
`pdfService` antes de sua inicialização assíncrona completar. O componente
`ExportButton.tsx` não aguarda a Promise de setup do serviço antes de
expor o botão como clicável.
Arquivo afetado: src/components/ExportButton.tsx (linha 47)
Causa provável: ausência de await no método initializePdfService()
Risco estimado: baixo. Mudança localizada em um único componente,
sem impacto em lógica de negócio ou dados.
Critérios de aceite sugeridos:
- exportação conclui com sucesso após a correção
- botão permanece desabilitado durante inicialização do serviço
- teste unitário cobre o caso de chamada antes do setup completar
Este problema atende aos critérios do gate ai-ready. Aguardando
decisão do responsável para prosseguir.O agente aplica a label status:ai-ready e move a issue para a coluna correspondente no Projects.
Etapa 5 — O humano aplica o gate
O dev abre a issue, lê o diagnóstico, confirma que faz sentido e mantém a label status:ai-ready. Esse gesto explícito é o gate. Sem ele, o agente não age.
Etapa 6 — O agente abre o pull request
Com o gate aplicado, o workflow dispara novamente. O agente lê os arquivos afetados, gera a correção, cria uma branch fix/export-button-async-init e abre um PR com o seguinte corpo:
Corrige: #147 — Exportação de PDF falha silenciosamente
Problema: ExportButton chamava pdfService.generate() antes da
inicialização assíncrona do serviço completar.
Solução: adicionado await em initializePdfService() e estado de
loading no botão durante o setup, prevenindo cliques prematuros.
Arquivos alterados:
- src/components/ExportButton.tsx
- src/services/pdfService.ts (ajuste no tipo de retorno)
Testes adicionados:
- ExportButton.test.tsx: caso de clique antes do setup completar
Alternativas descartadas: memoização do serviço no nível do módulo
descartada por introduzir estado global desnecessário.
Confiança: alta. Causa identificada com precisão no stack trace.O PR passa pela CI: typecheck, lint, testes unitários, build. Tudo verde. O GitHub notifica o dev para revisão.
Etapa 7 — O humano revisa e mergeia
O dev lê o diff, valida a lógica, confirma que os testes cobrem o caso e aprova o merge. O PR é mergeado via rebase.
O agente fecha a issue original com um comentário linkando o PR. O gateway registra o ciclo no Notion: tipo de problema, solução aplicada, tempo da primeira ocorrência até o merge (neste caso, 6 horas), e assertividade do diagnóstico (confirmada pelo dev na revisão).
O que este ciclo demonstra
O usuário encontrou o bug às 14h. A issue estava criada, triada e com diagnóstico às 14h12. O PR estava aberto às 14h18. O dev revisou e mergeou às 20h, sem precisar reproduzir o problema do zero, sem procurar contexto em Slack ou Notion, e sem triagem manual.
O tempo de resolução foi de 6 horas. O tempo de atenção humana no ciclo inteiro foi de aproximadamente 10 minutos.

O que o padrão não resolve
Ser honesto sobre as limitações é parte do que torna um padrão útil.
A SIA pressupõe clareza de visão de produto. Uma equipe sem direção vai apenas corrigir mais rápido coisas que talvez não devessem existir. O padrão também pressupõe testes automatizados robustos como condição para que qualquer PR do agente passe pela CI.
Há um risco específico que vale nomear: agentes gerando PRs em cadência alta podem criar uma ilusão de progresso. Muitos commits, muitos fechamentos de issue, e métricas de negócio estagnadas. A medida de sucesso da SIA é a redução do tempo entre identificação de problema e resolução com impacto mensurável para o usuário, não o volume de PRs gerados.
Onde o padrão funciona bem:
Aplicações com usuários ativos que geram sinais contínuos de qualidade
Times pequenos onde o custo de triagem manual é alto em relação ao headcount
Codebases com cobertura de testes suficiente para que CI seja gate confiável
Produtos internos onde o ciclo feedback-correção precisa ser mais curto que o processo padrão permite
Equipes com pelo menos uma pessoa capaz de revisar código gerado por agente com senso crítico
Por onde começar
A pergunta mais frequente quando apresento esse padrão é: “por onde começo?”. A resposta depende do maior gargalo atual do seu processo.
Se sua equipe perde tempo triando manualmente um volume alto de reports, comece pela camada de normalização: o gateway que converte sinais em issues estruturadas já resolve boa parte do problema. Se problemas chegam sem contexto suficiente para diagnóstico, comece pelo widget de feedback e pela integração com ferramenta de observabilidade. Se o processo de triagem funciona mas a correção demora, aí sim faz sentido investir na camada de agente.
Começar pela camada de agente sem ter as anteriores funcionando é o atalho que mais custa. Agente sem contexto rico gera diagnósticos genéricos. Diagnósticos genéricos geram PRs que não passam em revisão. PRs que não passam geram desconfiança no sistema inteiro.
A SIA é um padrão de acumulação. Cada camada bem implementada aumenta o valor da próxima. A pressa em chegar à autonomia do agente é o caminho mais certo para abandonar o sistema em três meses.
Considerações finais
A ideia central do padrão é deceptivamente simples: aplicações que capturam feedback estruturado, processam esse feedback com automação inteligente e fecham o loop com revisão humana criteriosa ficam progressivamente melhores com o tempo. Por processo, não por design heroico.
O “self” no nome significa que o motor de melhoria está dentro do sistema, alimentado pelo uso real, em vez de depender exclusivamente da capacidade de atenção de uma equipe para capturar, processar e agir sobre sinais que chegam continuamente.
Com as ferramentas disponíveis hoje: observabilidade moderna, modelos de linguagem capazes de raciocinar sobre código, infraestruturas de agentes com controle granular. O padrão é implementável por equipes de qualquer tamanho. O investimento inicial é real. O retorno, se bem executado, é composto.
“O objetivo é uma aplicação onde o custo de quebrar e corrigir cai progressivamente com o tempo.”
Guilherme Favaron é CTO do GRI Institute e autor de “Desbloqueando a Inteligência Artificial”. Escreve sobre IA aplicada a negócios na newsletter IA Aplicada.