

O fim do tokenmaxxing: por que usar modelo de fronteira para tudo acabou
Quando o modelo capaz fica barato e o protocolo de agente fica trivial de escalar, a vantagem migra de qual modelo voce usa para qual arquitetura de custo voce desenha.

Há algumas semanas argumentei aqui que o código estava deixando de ser o ativo escasso, comoditizado pela mesma IA que o escreve (O fim do código como ativo). Esta semana o mesmo movimento de comoditização apareceu uma camada acima, no próprio modelo de fronteira. Três fatos do dia 30 de junho contam a história quando lidos juntos, e foi o radar de inteligência que mantenho em código aberto (radar de inteligência de mercado) que os colocou na mesma mesa.
O primeiro é um lançamento de modelo. O segundo é a maior revisão de um protocolo de agentes desde que ele existe. O terceiro é uma reportagem de mercado sobre empresas cortando gasto com IA. Separados, são três notas soltas. Juntos, marcam o fim de uma prática que dominou os últimos dois anos: jogar o modelo mais caro em cima de todo problema, o que a comunidade apelidou de tokenmaxxing.
Organizei o argumento em sete pontos, na ordem em que eles se constroem.
01. O que era tokenmaxxing
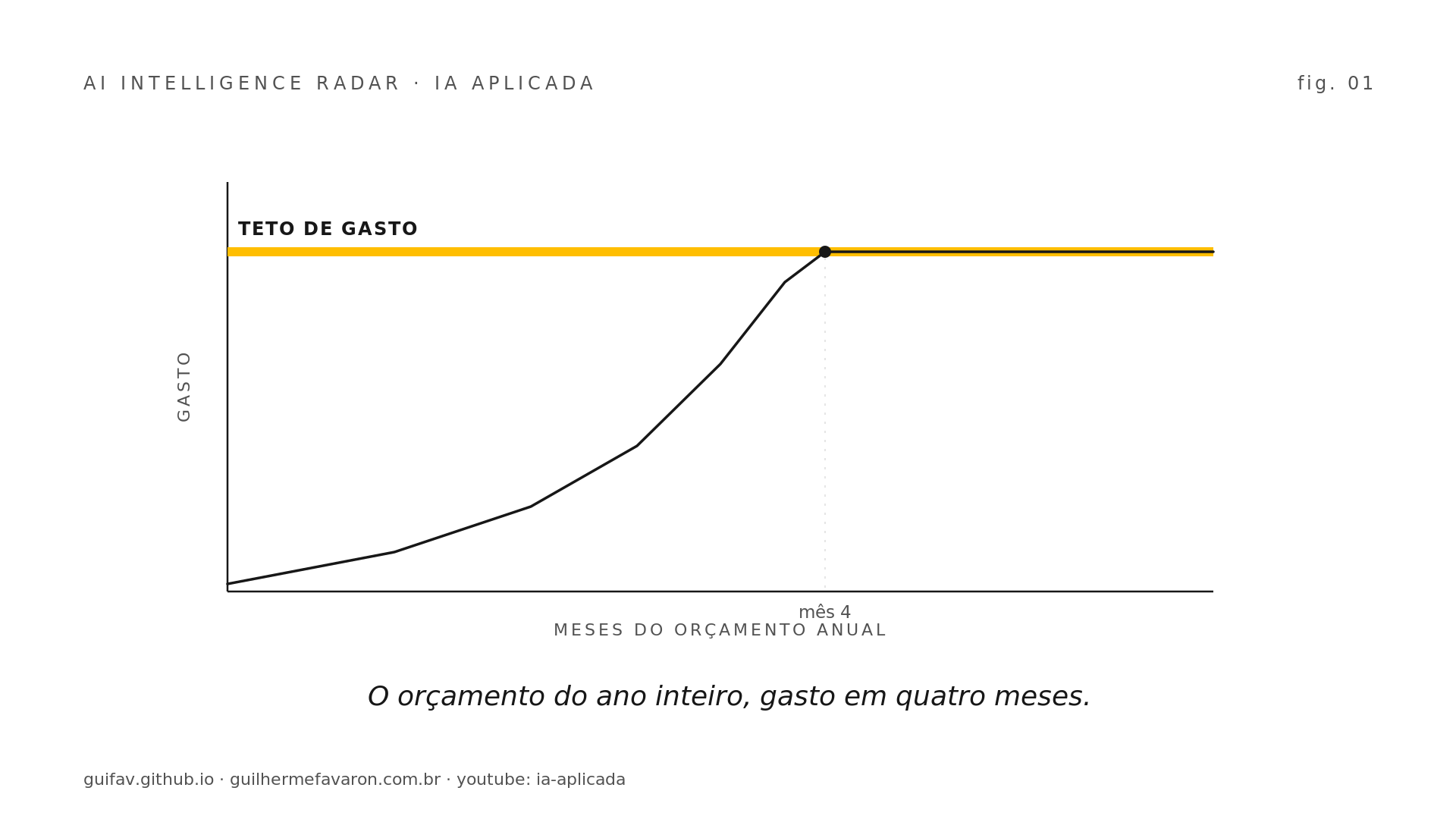
Tokenmaxxing é a prática de resolver qualquer tarefa com o modelo mais capaz disponível, sem perguntar se a tarefa exige aquela capacidade. Classificar um e-mail, extrair um campo de um PDF, resumir uma reunião e provar um teorema iam todos para o mesmo modelo de topo, faturados na mesma tarifa premium. Durante 2024 e 2025 isso fez sentido operacional: a diferença de qualidade entre o topo e o meio da tabela era grande o suficiente para justificar pagar caro por margem de segurança, e o orçamento de IA era tratado como investimento estratégico fora de questionamento.
A reportagem da CNBC de 26 de junho coloca número nessa cultura: usar modelo de fronteira para tudo responde por cerca de 95% do uso enterprise atual. Era a norma. O que mudou é que a norma ficou cara demais para sobreviver ao primeiro ciclo de orçamento sério.
02. O mercado puxou o freio
A mesma reportagem documenta o outro lado da curva. A Uber colocou um teto base de USD 1.500 por mês por funcionário depois de queimar o orçamento anual de IA em quatro meses. A Lindy AI migrou 100% do tráfego que rodava em Claude para DeepSeek e viu o custo despencar. O padrão que se repete entre as empresas citadas tem três peças:
teto de gasto mensal por funcionário,
roteamento de cada tarefa para o modelo mais barato que resolve, e
exigência de ROI comprovado antes de aprovar budget novo.
O pano de fundo financeiro confirma a pressão. Anthropic e OpenAI entraram com pedido de IPO confidencial em junho, com run-rates reportados de cerca de USD 47 bilhões e USD 25 bilhões respectivamente (números reportados, sem auditoria pública, e o NYT sugere que a OpenAI pode adiar o IPO para 2027). Os dois maiores fornecedores de fronteira se preparam para o mercado público no exato momento em que os clientes começam a racionalizar gasto. Roteamento de modelo deixa de ser otimização de engenheiro e passa a virar linha de governança financeira reportada a board.
03. A fronteira ficou barata: Claude Sonnet 5
No mesmo 30 de junho, a Anthropic lançou o Claude Sonnet 5. Modelo multimodal, janela de 1.000.000 de tokens de input e até 64 mil de output, a USD 3,00 por milhão de tokens de input e USD 15,00 por milhão de output, identificador de API claude-sonnet-5. Sonnet 5 fica abaixo do topo da própria Anthropic, com Opus 4.8 e Fable 5 acima em avaliação agregada. O ponto é exatamente esse. Sonnet 5 entrega raciocínio, código e matemática no quarto e terceiro lugares dos agregados de benchmark a uma fração do preço do tier Opus, com contexto suficiente para ingerir uma base de código inteira em um único request.
Vale separar o que é evidência do que é alegação, porque a diferença importa para a decisão. A data, o preço, o contexto e o identificador de API são fatos do system card. O score independente vem da Artificial Analysis, que coloca o modelo em 1618 de Elo no GDPval-AA, terceiro lugar, evidência forte porque é terceiro avaliando. Já os números de USAMO 79,5%, ChartMuseum 87% e CharXiv 88% são self-reported pela Anthropic e devem ser tratados como "alegação de fornecedor" até verificação independente. Latência e throughput citados vieram de página da Anthropic e pedem validação no endpoint oficial. A decisão de adotar Sonnet 5 como tier médio se sustenta nos fatos que forem possível auditar, sem depender dos números "com asterisco".
04. A infraestrutura de agente ficou barata: MCP stateless
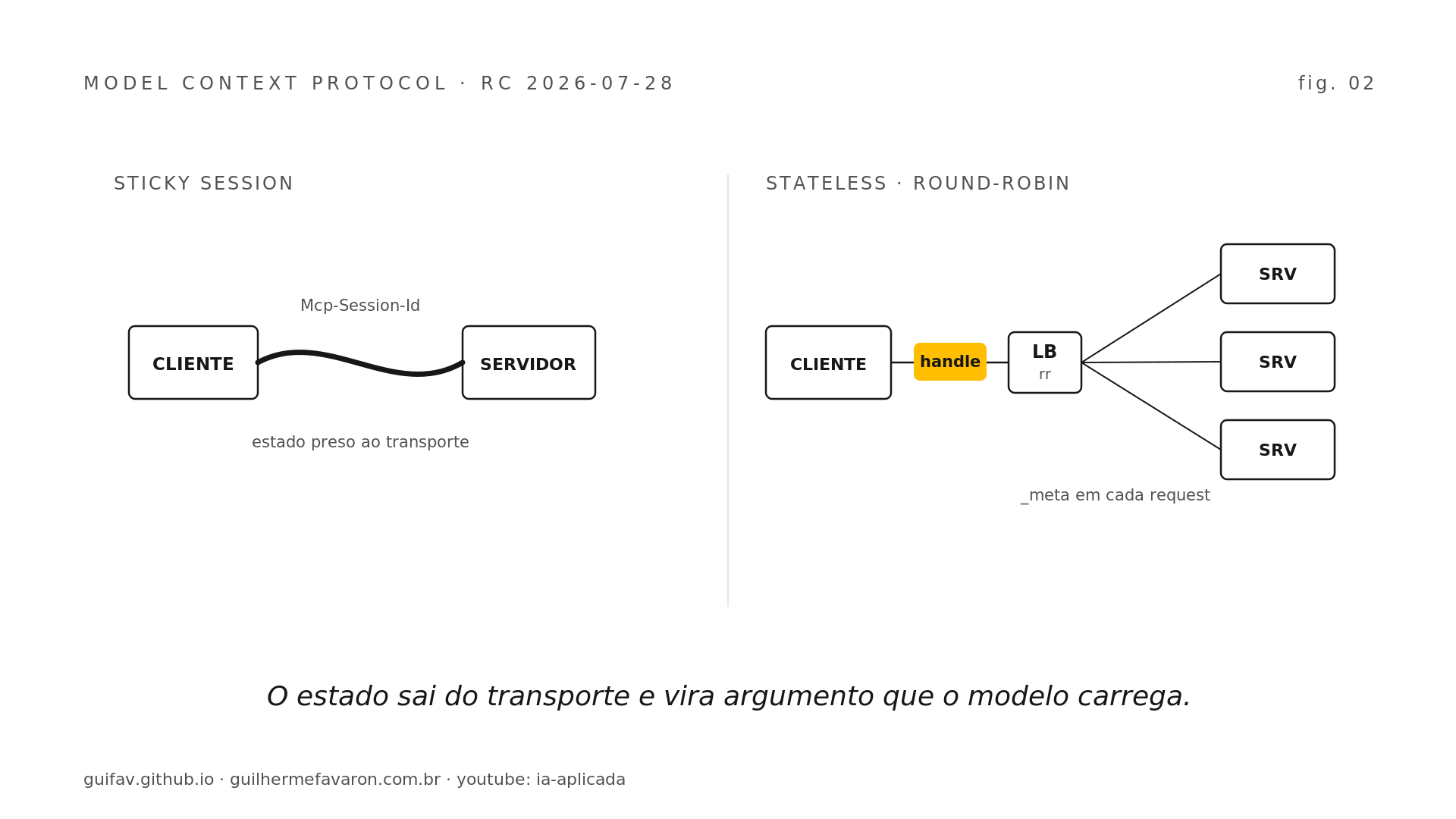
O segundo fato técnico é o que torna o roteamento viável em escala. O Model Context Protocol publicou o Release Candidate da spec 2026-07-28, descrito pelo próprio projeto como a maior revisão desde o lançamento, com a versão final marcada para 28 de julho e uma janela de validação de dez semanas em que os SDKs Tier 1 ficam obrigados a suportar. A mudança de fundo é o core ficar stateless: removem o handshake de inicialização (SEP-2575) e o header de sessão Mcp-Session-Id (SEP-2567), e a versão do protocolo, as capabilities e a info do cliente passam a viajar em metadados em cada request, com um método novo de descoberta sob demanda.
A consequência operacional é direta. Um servidor MCP remoto que antes exigia sticky session, store de sessão compartilhado e inspeção profunda no gateway agora roda atrás de um load balancer round-robin comum, com clientes cacheando a lista de ferramentas até o tempo de vida expirar. O estado passa a ser explícito: uma ferramenta emite um identificador (um basket_id, um browser_id) e o modelo devolve esse identificador como argumento na próxima chamada, o que deixa o estado visível ao modelo em vez de escondido no transporte. Como há breaking changes, quem mantém servidor MCP próprio ganha em começar a leitura do changelog agora, antes de 28 de julho. Operar agente em produção fica mais barato e mais simples na mesma semana em que o modelo capaz ficou barato.
05. Model routing vira disciplina de gestão
Juntando as três peças, o roteamento de modelo assume o centro da operação de quem roda IA. A forma madura é uma política de tiers explícita: tarefa simples vai para um modelo open-weight barato (DeepSeek, Kimi K2.7 Code, GLM-5.2 são os candidatos que aparecem no radar e que eu uso), tarefa média vai para Sonnet 5, e só o raciocínio mais duro chega ao Opus. Cada request desce a escada até o degrau mais barato que ainda resolve, e o que torna isso defensável perante o board é instrumentar custo por fluxo, métrica que a maioria das operações ainda não tem.
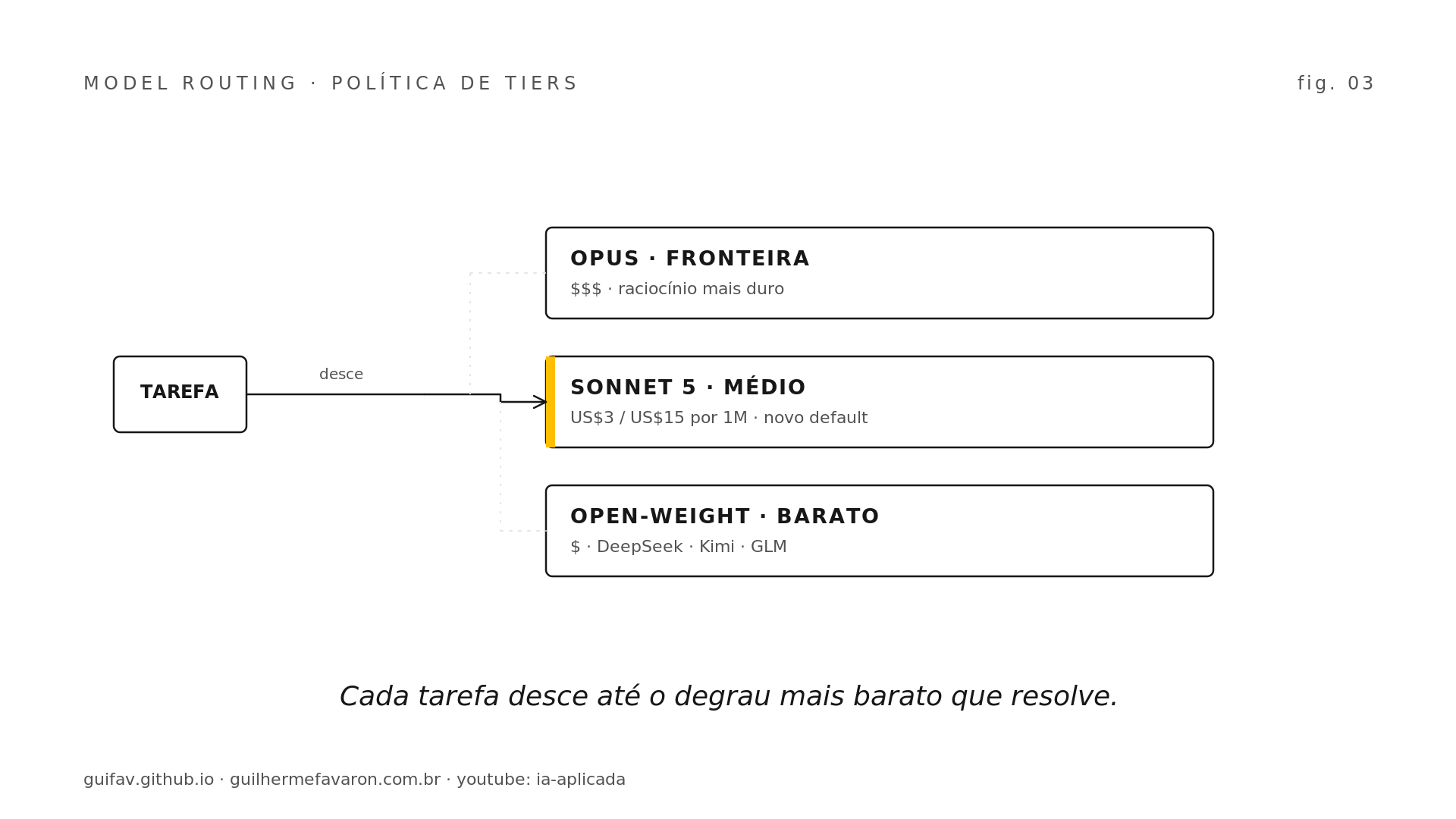
O degrau do meio é o que muda mais de figura com o Sonnet 5. Para a maioria das tarefas de agente, código assistido e análise de documento, o tier médio passa a resolver com qualidade alta sem o custo do topo. O topo deixa de ser o default e volta a ser o que sempre deveria ter sido: a exceção cara, reservada para o problema que de fato a exige.
06. O que é hype nisso
Um bom radar precisa identificar separadamente o ruído e o sinal . Os números de benchmark self-reported do Sonnet 5 circulam como se fossem definitivos, e não são até alguém de fora confirmar. O número confiável hoje é o GDPval-AA da Artificial Analysis, terceiro independente. A narrativa de torcida Anthropic contra OpenAI também rende manchete e explica pouco: a própria TechCrunch argumenta que os dois enfrentam o mesmo gargalo regulatório, então a rivalidade fica como entretenimento e o sinal está no gargalo compartilhado. E a onda de busca agêntica do Google (Antigravity, Gemini 3.5 Flash, Search Agents) é tendência real de agentes embutidos em consumo, com um detalhe que o calendário desmonta por se tratar de um anúncio original de maio (mas que efetivamente ainda nao chegou na ponta).
A regra que uso para mim, e que recomendo, é simples de enunciar e difícil de seguir: número com asterisco é alegação até virar evidência, e a fonte primária vale mais que o agregador que a repackageia.
07. O que levar para a sua empresa
Quatro conclusões, em ordem de incômodo.
Primeira: frontier-para-tudo acabou como default. Se a sua operação roda toda tarefa no modelo mais caro, ela está pagando tier premium por trabalho que o tier médio resolve, e o primeiro ciclo de orçamento sério vai expor isso como a Uber expôs o próprio.
Segunda: roteamento é disciplina de gestão, com política de tiers e custo por fluxo medido. Desenhar essa política e instrumentar o custo é o que transforma a área de IA de centro de custo crescente em dona de uma arquitetura que entrega o mesmo resultado por uma fração do gasto. Esse é o argumento que sustenta IA na empresa perante quem assina o cheque.
Terceira: a infraestrutura barata chegou junto com o modelo barato. MCP stateless remove o motivo técnico mais comum para agente em produção sair caro. Quem mantém servidor próprio tem uma data, 28 de julho, e um changelog para ler antes dela.
Quarta, e a que compõe com tudo que já escrevi aqui: quando todo concorrente tem acesso aos mesmos modelos de fronteira pela mesma API, o modelo para de ser vantagem. O que sobra como fosso é o que não se compra por API, o ativo de dados proprietário coletado ao longo de anos que descrevi em O ativo invisível, agora somado à arquitetura de custo que decide qual modelo toca qual tarefa. O modelo de fronteira é a camada fina e comoditizada em cima. A vantagem real é a estrutura que sustenta embaixo.

A pergunta que fica para o seu planejamento é direta: se o modelo mais inteligente do mercado custasse o mesmo que o mais barato amanhã, o que na sua operação ainda seria difícil de copiar? A resposta a essa pergunta é a única coisa em que vale a pena investir antes do próximo lançamento tornar o resto commodity.
Fontes primárias consultadas: blog oficial do Model Context Protocol (RC 2026-07-28), system card do Claude Sonnet 5 cruzado em agregador de stats, blog do Google. Jornalismo com fontes nomeadas: CNBC (corte de gasto enterprise) e TechCrunch (gargalo regulatório). Números de benchmark marcados como self-reported são alegação da Anthropic até verificação independente; o número auditado citado é o GDPval-AA da Artificial Analysis. Run-rates de Anthropic e OpenAI são reportados, sem auditoria pública. Sinais de X foram tratados apenas como detector de fumaça, sem citação social como evidência. Este ensaio nasceu de uma rodada do AI Intelligence Radar, sistema de curadoria que mantenho em operação própria.