

Como Criar um Modelo de Machine Learning a Partir de Planilhas: Guia Completo
Pipeline completo em 5 etapas: análise exploratória, engenharia de features, preparação, modelagem e aplicação, com código disponível.

Transformar dados de planilhas em modelos preditivos de machine learning é mais acessível do que parece. O processo envolve 5 etapas principais: análise exploratória, engenharia de features, preparação dos dados, modelagem supervisionada (classificação e regressão) e implantação. Com cerca de 5 milhões de registros de voos dos EUA, é possível construir um modelo que prevê atrasos com ROC-AUC de 0,75 e erro médio de 18 minutos na estimativa de tempo.
Este artigo detalha cada etapa de um pipeline completo de machine learning, desde a planilha bruta até uma aplicação funcional. O caso de uso demonstra previsão de atrasos em voos, mas a metodologia se aplica a diversos cenários empresariais: previsão de churn, análise de processos jurídicos, manutenção preditiva de equipamentos ou projeções financeiras.
Quais são os casos de uso práticos para modelos preditivos baseados em planilhas?
Qualquer organização com dados históricos tabulados pode criar modelos de previsão. Escritórios de advocacia analisam potencial de sucesso em processos. Fábricas preveem falhas em equipamentos. Empresas de serviços estimam probabilidade de renovação ou churn. Times de marketing avaliam campanhas antes do lançamento. A chave está em ter dados estruturados com variáveis que se correlacionam com o resultado desejado.
O denominador comum entre esses casos é a existência de um histórico de decisões ou eventos com seus respectivos resultados. Se uma planilha contém registros passados com a informação que se deseja prever, há potencial para um modelo de machine learning.
No caso demonstrado neste artigo, três planilhas com aproximadamente 5 milhões de voos dos Estados Unidos e 40 variáveis servem como base para prever duas coisas: se um voo vai atrasar (classificação binária) e quanto tempo vai atrasar (regressão).

Como funciona a estrutura de um projeto de machine learning?
Um projeto de ML bem organizado segue uma estrutura de pastas que separa dados brutos, processados e prontos para modelagem. Os notebooks Jupyter contêm o código e suas saídas documentadas. A pasta de modelos armazena os algoritmos treinados. Relatórios guardam visualizações, e arquivos auxiliares ficam em uma pasta de código-fonte separada.
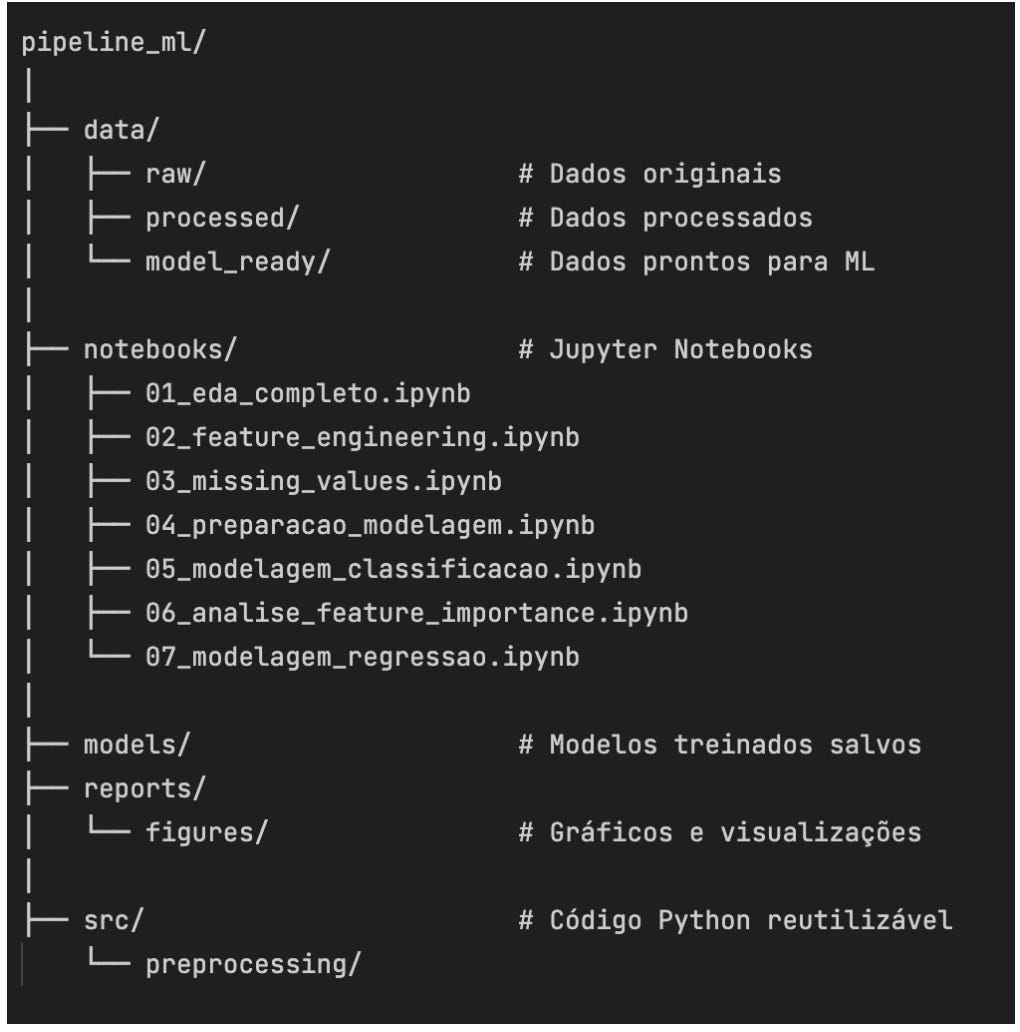
A organização proposta:
data/: dados brutos (raw), processados e prontos para modelagem
notebooks/: arquivos Jupyter com o pipeline de ML documentado
models/: modelos de machine learning salvos após treinamento
reports/: imagens e visualizações geradas para análise
src/: scripts auxiliares para transformações e testes
Os Notebooks Jupyter são particularmente úteis nesse contexto porque permitem combinar texto explicativo com código executável, mantendo as saídas de cada função visíveis. Isso facilita a documentação e o compartilhamento do trabalho.

O que é Análise Exploratória de Dados (EDA) e por que ela é crítica?
A EDA é a fase de compreensão profunda dos dados antes de qualquer modelagem. Envolve carregamento, estatísticas descritivas completas, visualizações que revelam insights e identificação de padrões e outliers. No caso dos voos, a análise revelou que 56% dos voos são adiantados, 18% atrasam mais de 15 minutos, e existem padrões claros por horário, dia da semana e companhia aérea.
")
Pular essa etapa é um erro comum que compromete todo o projeto. A EDA responde perguntas fundamentais: qual a distribuição das variáveis? Existem valores ausentes? Há correlações óbvias? Quais features parecem mais relevantes?
No dataset de voos, a análise exploratória mostrou que a maioria dos voos não apenas chega no horário, mas chega antes do previsto. Os atrasos significativos (acima de 15 minutos) representam menos de um quinto do total. Esse desbalanceamento de classes é uma informação crucial para a modelagem.
O que é Engenharia de Features e como ela impacta a qualidade do modelo?
Engenharia de features transforma dados brutos em variáveis úteis para algoritmos de ML. O processo inclui limpeza de dados ausentes, normalização de escalas, codificação de categorias e criação de novas variáveis derivadas. No projeto, foram tratados mais de 30 milhões de valores ausentes (redução de 97%) e criadas 20 novas features, incluindo período do dia, estação, taxas históricas de atraso e características geográficas.

Esta etapa é frequentemente subestimada, mas tem impacto direto na performance do modelo. Algoritmos de ML aprendem a partir das features fornecidas. Dados ruins ou pouco informativos geram previsões fracas, independentemente da sofisticação do algoritmo utilizado.
Exemplos de features criadas para o modelo de voos:
Temporais: período do dia (manhã, tarde, noite, madrugada), estação do ano, final de semana vs. dia útil
Históricas: taxas de atraso por aeroporto, por companhia aérea e por rota específica
Geográficas: estados de origem e destino, coordenadas
Uma boa engenharia de features aumenta a separação entre classes (”atrasou” vs. “não atrasou”) e fortalece a relação com a variável-alvo, melhorando métricas e robustez do modelo.
Como preparar os dados corretamente para modelagem de machine learning?
A preparação envolve quatro passos: seleção de features relevantes (25 no caso estudado), divisão estratificada dos dados (70% treino, 10% validação, 20% teste), balanceamento de classes para evitar viés, e salvamento dos objetos de pré-processamento para uso em produção. O split estratificado garante que a proporção de voos atrasados vs. pontuais se mantém igual em cada subconjunto.

Seleção de Features
Em vez de usar todas as 40 variáveis disponíveis, foram selecionadas 25 que demonstram relação efetiva com atraso ou pontualidade. Isso reduz ruído, acelera o treinamento e melhora a capacidade de generalização do modelo.
Split Estratificado
A divisão dos dados em treino, validação e teste não pode ser aleatória simples quando há desbalanceamento de classes. O split estratificado mantém as proporções originais em cada subconjunto, evitando vieses na avaliação.
Balanceamento de Classes
Como atrasos são menos frequentes que pontualidade, um modelo não ajustado “aprende” a sempre prever que o voo não atrasa. As técnicas de balanceamento (reamostragem ou pesos) forçam o algoritmo a dar mais importância aos casos de atraso.
Objetos de Pré-processamento
Scalers, encoders e outras transformações precisam ser salvos em disco. Na predição em tempo real, os mesmos parâmetros de normalização e codificação devem ser aplicados para manter consistência entre treino e produção.
Qual a diferença entre classificação e regressão em machine learning?
O projeto utiliza dois tipos de modelos supervisionados complementares. A classificação responde perguntas binárias: o voo vai atrasar ou não? O modelo separa dados em categorias distintas (atrasado vs. no horário). Já a regressão prevê valores contínuos: quanto tempo vai atrasar? O modelo estima um número em minutos. Juntos, entregam uma previsão completa e acionável para tomada de decisão.

A imagem ilustra essa distinção fundamental. No lado esquerdo, o modelo de classificação traça uma fronteira de decisão que separa os pontos vermelhos (atrasos) dos verdes (no horário). O resultado é categórico: sim ou não.
No lado direito, o modelo de regressão ajusta uma curva aos dados para estimar valores numéricos. Em vez de categorias, a saída é um número — no caso, os minutos de atraso esperados (±18 minutos de erro médio).
Na prática, a combinação dos dois modelos oferece mais valor que cada um isoladamente. O fluxo recomendado: primeiro, o classificador determina se há probabilidade de atraso. Se positivo, o regressor estima a magnitude. Essa abordagem em duas etapas permite calibrar limiares de decisão conforme o contexto de negócio.
Quais modelos de classificação funcionam melhor para prever eventos binários?
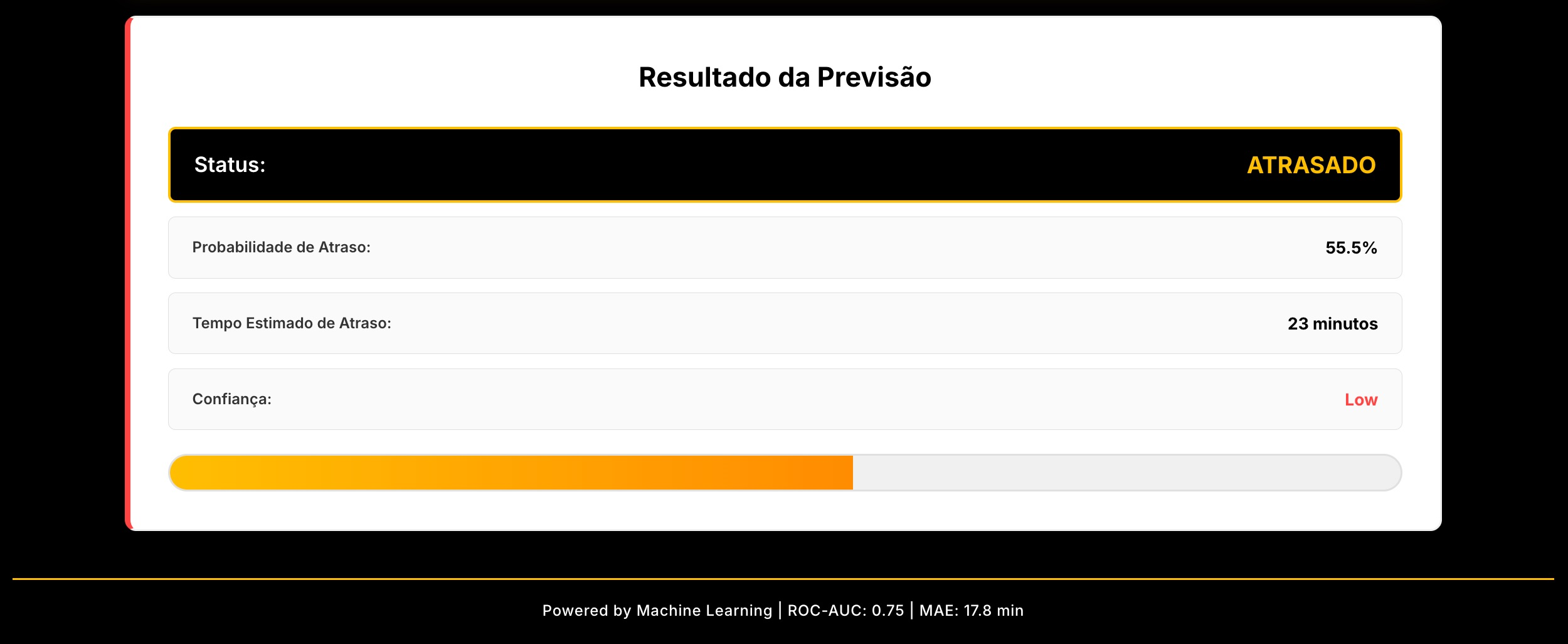
Para classificação binária (atraso sim/não), três modelos foram testados: SGD Classifier como baseline rápido, Random Forest (conjunto de árvores) e XGBoost (gradiente otimizado). O melhor resultado alcançou ROC-AUC de 0,75, F1-Score de 0,44 e Recall de 0,67. Isso significa que o modelo consegue capturar 67% dos atrasos reais, com boa separação entre classes.

Entendendo as Métricas
ROC-AUC (0,75): mede a capacidade de separar atrasos vs. pontuais ao longo de vários limiares de decisão. Valor 1,0 seria perfeito; 0,5 equivale a chute aleatório.
F1-Score (0,44): combina precisão e recall. Útil quando o custo do erro é assimétrico.
Recall (0,67): quantos atrasos reais o modelo consegue identificar. Importante quando o custo de “perder” um atraso é alto.
Data Leakage: A Armadilha Silenciosa
Durante o desenvolvimento, foi identificado e corrigido um problema de vazamento de dados (leakage). A variável DELAY_MINUTES vazava informação do futuro — ela só existe após o voo ocorrer, então não pode entrar no modelo que prevê “se vai atrasar”.
O processo de correção envolveu identificar features suspeitas, verificar importâncias e relações, retreinar sem as variáveis problemáticas e comparar métricas para garantir integridade dos resultados.

Como funciona a regressão para prever tempo de atraso em minutos?
Para prever quanto tempo um voo vai atrasar (variável contínua), foram testados quatro modelos: Linear Regression, Ridge Regression, Random Forest Regressor e XGBoost Regressor. Os resultados mostram MAE de 17,8 minutos (erro médio absoluto), RMSE de 36,04 minutos e R² de 0,0567. O R² baixo é esperado devido à alta variabilidade intrínseca de atrasos de voos.

Interpretando os Resultados
O MAE de 17,8 minutos significa que, em média, o modelo erra aproximadamente 18 minutos para mais ou para menos. O RMSE mais alto (36,04) indica que existem alguns erros grandes que são penalizados mais fortemente por essa métrica.
O R² de 0,0567 pode parecer preocupante, mas é comum na literatura de previsão de atrasos. A variabilidade é causada por fatores difíceis de capturar em dados tabulados: condições meteorológicas em tempo real, problemas operacionais, decisões de controle de tráfego aéreo e eventos imprevisíveis.
Como Usar na Prática
A recomendação é tratar a previsão como uma faixa, não um número exato. Por exemplo: “atraso esperado de 15 a 20 minutos”. A combinação com o modelo de classificação também agrega valor: primeiro determina-se se vai atrasar, depois estima-se quanto.
Para aplicações específicas, modelos segmentados por rotas, horários ou companhias podem oferecer precisão superior.
Qual arquitetura usar para um aplicativo de previsão de atrasos?
O aplicativo de previsão segue arquitetura em duas camadas: interface superior para seleção e ajuste de features (variáveis de entrada), e área inferior para exibição de resultados — previsão de atraso/pontualidade e tempo estimado quando aplicável. O limiar de decisão pode ser ajustado conforme o custo de negócio, sendo mais conservador para capturar mais atrasos.

A interface permite que usuários não-técnicos interajam com o modelo sem precisar escrever código. Cada feature pode ser ajustada individualmente: companhia aérea, aeroportos de origem e destino, horário do voo, dia da semana, entre outras.

O resultado apresenta tanto a classificação (atrasado ou pontual) quanto, no caso de previsão de atraso, o tempo estimado em minutos. Isso dá ao usuário informação acionável para tomada de decisão.
Quais são os próximos passos para levar um modelo de ML para produção?
Para produção robusta, quatro práticas de MLOps são essenciais: versionamento de dados, modelos e objetos de pré-processamento; configuração de inferência batch (D+1) e online (tempo real) conforme necessidade; monitoramento de drift de dados e performance com retreino automático; e logging de entradas/saídas com explicabilidade (feature importance, SHAP) para auditoria.

Versionamento
Assim como código, dados e modelos precisam de controle de versão. Ferramentas como DVC (Data Version Control) ou MLflow permitem rastrear qual versão de dados gerou qual modelo, facilitando reprodutibilidade e debugging.
Inferência Batch vs. Online
Nem toda aplicação precisa de predição em tempo real. Modelos que atualizam previsões diariamente (D+1) têm requisitos de infraestrutura muito menores. A escolha depende do caso de uso.
Monitoramento de Drift
Dados mudam ao longo do tempo. O modelo treinado em dados de 2024 pode perder performance em 2025 se padrões se alterarem. Alertas de degradação de métricas disparam retreino automático ou manual.
Explicabilidade
Para confiança operacional e compliance, é importante entender por que o modelo fez determinada previsão. Técnicas como feature importance e SHAP values mostram quais variáveis mais influenciaram cada resultado.
Checklist para implementar seu próprio pipeline de ML preditivo
Pré-requisitos
Dados históricos com a variável que se deseja prever
Ambiente Python com bibliotecas de ML (scikit-learn, XGBoost)
Jupyter Notebook ou ambiente equivalente para experimentação
Etapa 1: Análise Exploratória
Carregar e inspecionar os dados
Gerar estatísticas descritivas
Visualizar distribuições e correlações
Identificar valores ausentes e outliers
Etapa 2: Engenharia de Features
Tratar valores ausentes
Criar features derivadas relevantes
Codificar variáveis categóricas
Normalizar variáveis numéricas
Etapa 3: Preparação
Selecionar features relevantes
Dividir dados (treino/validação/teste)
Balancear classes se necessário
Salvar objetos de pré-processamento
Etapa 4: Modelagem
Treinar múltiplos algoritmos
Validar ausência de data leakage
Comparar métricas
Selecionar modelo final
Etapa 5: Aplicação
Criar interface de predição
Testar com dados novos
Documentar limitações
Quando NÃO usar essa abordagem?
Modelos preditivos baseados em dados tabulados não funcionam bem em três cenários: quando não há dados históricos suficientes (menos de algumas centenas de registros relevantes), quando a variável-alvo depende majoritariamente de fatores não capturáveis em planilhas (como decisões humanas subjetivas), ou quando a relação entre variáveis muda constantemente sem padrão detectável.
Também é importante reconhecer que modelos estatísticos trabalham com probabilidades, não certezas. Um modelo com 75% de acurácia ainda erra em 1 a cada 4 casos. Para decisões críticas, o modelo deve ser um apoio à decisão humana, não um substituto.
Por fim, a qualidade dos dados é determinante. O princípio “garbage in, garbage out” permanece válido: dados incorretos, incompletos ou enviesados produzem modelos problemáticos, independentemente da sofisticação técnica aplicada.
Recursos Complementares
O código completo do pipeline demonstrado neste artigo está disponível para download. O repositório inclui:
Notebooks Jupyter documentados para cada etapa
Dados de exemplo para testes
Modelos pré-treinados
Scripts de pré-processamento reutilizáveis
A metodologia apresentada funciona igualmente com dados de banco de dados SQL, PostgreSQL ou qualquer outra fonte estruturada. O conceito permanece o mesmo: dados tabulados com histórico de resultados podem alimentar modelos preditivos.
Artigo complementar ao vídeo “Pipeline de Machine Learning: Da Planilha à Aplicação”
Sobre o autor:
Guilherme Favaron é Executivo de Tecnologia com 18+ anos de experiência em transformação digital, especialista em IA aplicada a negócios, criador de 22+ aplicações de IA no MindApps.ai e autor do livro “Desbloqueando a Inteligência Artificial”. Mais sobre sua produção técnica: clique aqui.
Data de publicação: Janeiro 2026