

O que o Candy Crush ensina sobre IA aplicada ao produto
Três abordagens distintas de machine learning para um mesmo problema, e o que cada uma revela sobre como pensar projetos de IA em empresas


Candy Crush Saga é um dos jogos mobile mais bem-sucedidos da história. Lançado em 2012 pela King, hoje parte da Activision Blizzard, acumula bilhões de downloads e continua entre os aplicativos mais lucrativos em Android e iOS. Para a maioria das pessoas, é um passatempo simples. Você combina doces da mesma cor, eles explodem, você avança de nível.
Recentemente voltei a pensar sobre o jogo por um motivo específico. Um detalhe me chamou a atenção: como a King consegue manter uma progressão de dificuldade consistente através de mais de 15 mil níveis, lançando cerca de 15 novos por semana, sem que a experiência se degrade. A resposta envolve machine learning aplicado de forma bastante sofisticada, e as lições são diretamente transferíveis para qualquer organização que use IA para otimizar produto.
O problema, ao contrário do que parece, atraiu atenção acadêmica significativa. Há pelo menos três teses de mestrado no KTH Royal Institute of Technology, um paper oficial dos engenheiros da King, um projeto de Stanford no curso CS230 de deep learning, uma prova matemática de NP-dificuldade no arXiv, e trabalhos recentes da Universidade Roma Tre aplicando Deep Reinforcement Learning à classe de jogos match-3. Cada abordagem resolve o problema de uma forma diferente, e as diferenças revelam decisões de design que vão muito além de Candy Crush.
Este artigo tem três objetivos. Primeiro, documentar com algum rigor técnico o que a King construiu, porque a história é genuinamente interessante e pouco conhecida fora de círculos especializados. Segundo, comparar as três abordagens principais que foram publicadas: MCTS, supervised learning com CNN, e Deep Q-Network. Terceiro, extrair princípios aplicáveis a projetos de IA em contextos empresariais que não têm nada a ver com jogos.
O problema real que a King enfrentava
A economia do Candy Crush depende de progressão constante. Se os níveis param de sair, os jogadores engajados terminam o conteúdo disponível e saem. Se saem em ritmo errado ou com dificuldade mal calibrada, a curva de retenção se deteriora. Com dezenas de milhões de jogadores ativos, o custo de um erro de calibração é grande.
O problema técnico específico é o seguinte. Cada novo nível precisa ter uma taxa de sucesso humano médio (AHSR, na terminologia interna da King, Average Human Success Rate) dentro de uma faixa calibrada para manter a experiência de flow. Uma taxa muito alta indica que o nível é fácil demais e o jogador se entedia. Uma taxa muito baixa indica que é difícil demais e o jogador desiste. A faixa-alvo varia conforme a posição do nível na jornada, com picos deliberados de dificuldade em posições específicas para criar momentos de desafio.
Até meados da década passada, a calibração era feita por testers humanos. Jogadores profissionais jogavam o mesmo nível cerca de 20 vezes, registravam resultados e escreviam relatórios. O processo levava aproximadamente uma semana por nível. Para um ritmo de 15 níveis novos por semana, isso exigia uma equipe grande, introduzia um gargalo estrutural no pipeline de produção, e limitava quantas iterações de design cada nível poderia receber antes de ser lançado.
A complexidade matemática escondida
Antes de entrar nas abordagens de machine learning, vale estabelecer que o problema é genuinamente difícil do ponto de vista teórico.
Em 2014, Toby Walsh publicou no arXiv um paper curto e preciso chamado “Candy Crush is NP-hard”. A prova usa uma redução a partir do 3-SAT, o problema canônico NP-completo, mostrando que encontrar a sequência ótima de movimentos em um nível arbitrário de Candy Crush é pelo menos tão difícil quanto satisfazer uma fórmula booleana em forma normal conjuntiva. Sob as conjecturas padrão em complexidade computacional (especificamente P ≠ NP), isso significa que não existe algoritmo de tempo polinomial para resolver otimamente o jogo, e é improvável que tal algoritmo venha a ser descoberto.

Esse resultado teórico tem uma implicação prática importante. Como força bruta é inviável, qualquer sistema que queira jogar Candy Crush em escala precisa usar heurísticas, amostragem estatística, ou aprendizado a partir de dados. Não há atalho analítico.
A tese de Erik Poromaa (KTH, 2017) reporta uma estimativa empírica que reforça essa intuição. Para o nível 13 do jogo, o espaço de estados (o conjunto de todas as configurações possíveis do tabuleiro considerando o fluxo de doces caindo) foi estimado em aproximadamente 10 elevado a 182. Para comparação, o universo observável contém na ordem de 10 elevado a 80 átomos, e existem aproximadamente 10 elevado a 50 configurações legais em um tabuleiro de xadrez. Um único nível de Candy Crush tem um espaço de estados muitas ordens de magnitude maior que o jogo completo de xadrez.
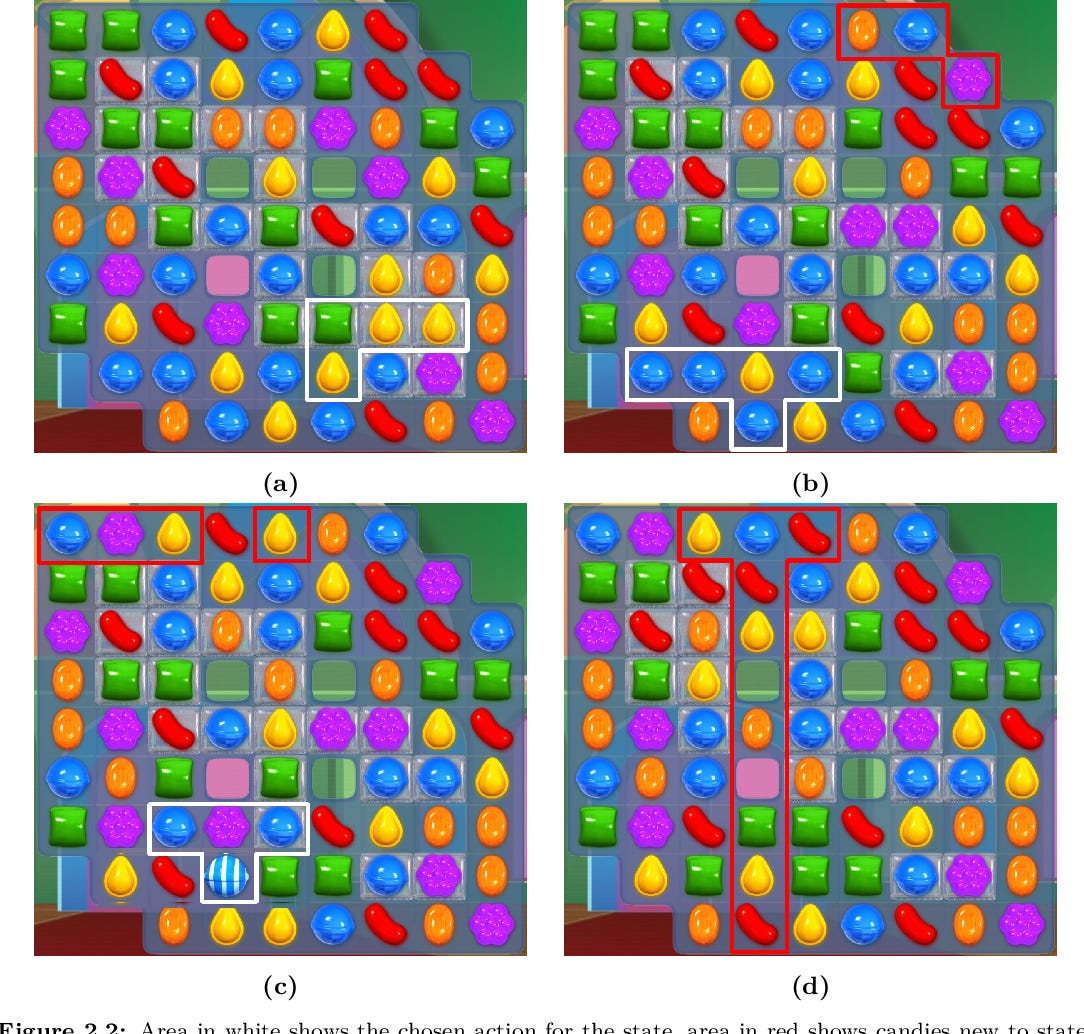
Esse número também explica por que o jogo tem uma propriedade interessante: mesmo que você jogue o mesmo nível milhares de vezes, é estatisticamente improvável que as mesmas configurações se repitam. A “previsibilidade do imprevisível” que jogadores percebem vem exatamente dessa vastidão.
Abordagem 1: Monte Carlo Tree Search
A primeira tentativa séria de automatizar a estimativa de dificuldade veio na tese de mestrado de Erik Poromaa em 2016, publicada em 2017, com o título “Crushing Candy Crush: Predicting Human Success Rate in a Mobile Game using Monte-Carlo Tree Search”.
Monte Carlo Tree Search é a família de algoritmos que também está por trás de sistemas como o AlphaGo. A intuição é a seguinte: a partir do estado atual, simule milhares de jogos completos escolhendo ações por algum critério (no caso mais simples, aleatoriamente), registre quais jogos terminam em sucesso, e use essa estatística para decidir qual ação tomar no estado real.
A aplicação a Candy Crush enfrenta dois problemas principais. O primeiro é o branching factor alto. Em um tabuleiro 9x9 com seis cores de doces, há dezenas de movimentos legais em cada posição, e o jogo tem 40 ou mais movimentos por nível. A árvore de busca cresce muito rápido. O segundo é a aleatoriedade intrínseca do jogo: quando você elimina doces, novos doces caem em posições aleatórias, o que significa que duas simulações a partir do mesmo estado podem seguir trajetórias completamente diferentes. Isso exige muitas simulações por estado para ter estimativas estáveis.
Poromaa reportou resultados razoáveis superando métodos anteriores de teste manual, mas com limitações claras em custo computacional. A abordagem funciona, mas não escala para o ritmo de produção da King sem hardware significativo.
Abordagem 2: Supervised Learning com CNN (a solução em produção da King)
A abordagem que eventualmente foi para produção está documentada no paper “Human-Like Playtesting with Deep Learning”, de autoria de Stefan Gudmundsson, Philipp Eisen, Erik Poromaa, Alex Nodet, Sami Purmonen, Bartlomiej Kozakowski, Richard Meurling e Lele Cao, todos engenheiros da King, publicado em 2018 na IEEE Conference on Computational Intelligence and Games.
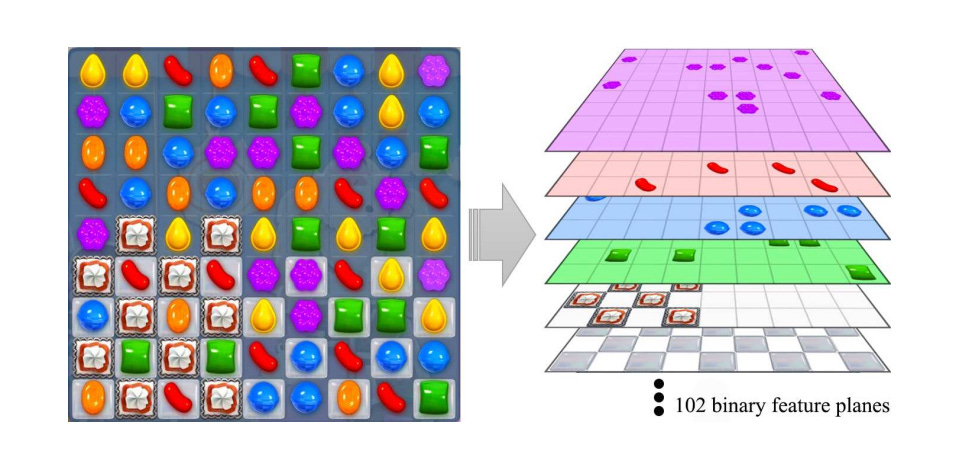
A arquitetura combina três elementos.
Representação do estado. O tabuleiro é codificado como um tensor binário com aproximadamente 102 feature planes. Cada plano é uma matriz binária do tamanho do tabuleiro onde cada célula indica a presença ou ausência de um atributo específico: cada cor de doce tem seu plano, cada tipo de doce especial tem seu plano (strip bombs horizontais, strip bombs verticais, wrapped bombs, color bombs), obstáculos como geleias e chocolates têm planos próprios, e o objetivo corrente do nível é codificado em planos adicionais. Essa representação é essencialmente equivalente ao input de uma rede neural convolucional aplicada a uma imagem, com a diferença de que os canais são semânticos em vez de RGB.
Dataset de decisões humanas. A King coletou aproximadamente 12 milhões de pares estado-ação (1.2 × 10 elevado a 7) de jogadores reais em Candy Crush Saga e Candy Crush Soda Saga. Cada par registra a configuração do tabuleiro em um determinado momento e a ação que o jogador humano tomou em seguida. Isso é o equivalente, em escala, a um dataset de visão computacional como o ImageNet, mas com configurações de jogo e decisões em vez de imagens e rótulos.
Rede neural convolucional. Uma CNN é treinada por aprendizado supervisionado para prever, dada uma configuração do tabuleiro, a distribuição de probabilidade sobre as ações que um humano típico tomaria. O output não é uma única ação determinística, é uma distribuição. Em inferência, o agente amostra dessa distribuição, o que preserva a variabilidade de comportamento humano.
O pipeline de simulação então usa esse agente como substituto de testers humanos. O agente joga cada novo nível centenas ou milhares de vezes, e a taxa de sucesso observada serve como estimativa da AHSR esperada quando o nível for lançado para jogadores reais.
O paper reporta que a abordagem CNN apresenta menor erro absoluto médio (MAE) que MCTS, maior correlação com dificuldade real observada em produção, e opera em uma fração do tempo computacional. O ganho operacional é que o playtesting que levava sete dias passou a ser feito em menos de um minuto por nível.
Há uma sutileza técnica importante aqui. A rede não está aprendendo a jogar otimamente, está aprendendo a reproduzir a distribuição empírica de comportamento humano. Isso é fundamental e vou voltar ao ponto.
Abordagem 3: Deep Q-Network (a perspectiva acadêmica)
Uma perspectiva alternativa interessante aparece no projeto de Bowen Deng no curso CS230 de Deep Learning em Stanford, no inverno de 2020, intitulado “Learn to play Candy Crush”. Esse trabalho adota uma abordagem de reinforcement learning com Deep Q-Network (DQN), e é instrutivo exatamente porque as decisões de design são diferentes.
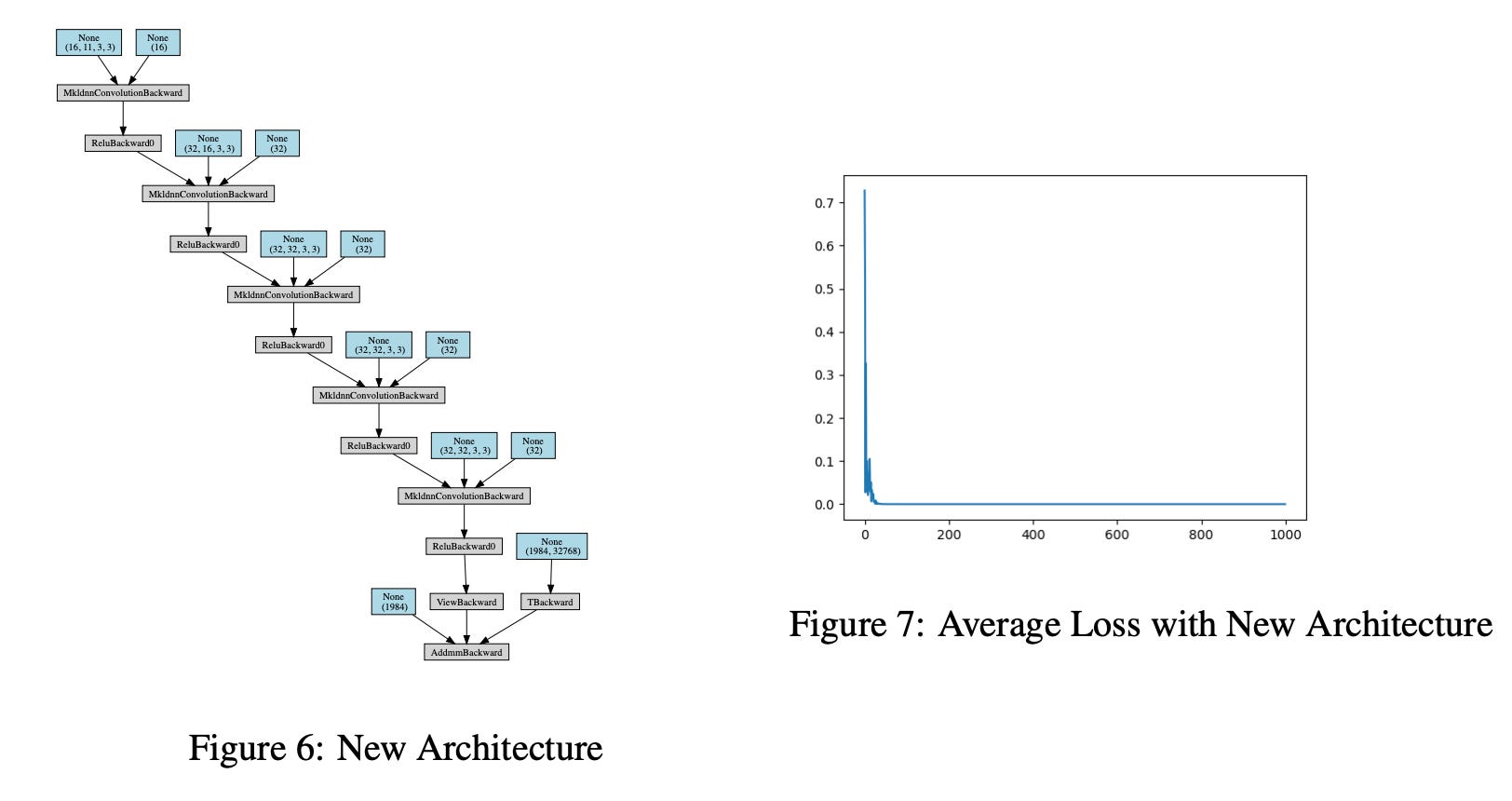
Deng trabalha com um setup simplificado: tabuleiro 10x10 sem obstáculos, 40 movimentos por jogo. O estado é representado como uma matriz de dimensão (C + S) × N × N, onde C é o número de cores de doces, S é o número de doces especiais, e N é o tamanho do tabuleiro. A representação é conceitualmente similar à da King, embora com menos feature planes por ter escopo reduzido.
O espaço de ações é de 2 × N × (N − 1) ações possíveis por posição: o agente pode escolher uma célula que não esteja na coluna mais à direita e trocar com a vizinha à direita, ou escolher uma célula que não esteja na linha inferior e trocar com a vizinha abaixo. Em um tabuleiro 10x10, isso resulta em 180 ações possíveis, o que já é um espaço de ação razoavelmente grande para reinforcement learning.
A arquitetura final, depois de várias iterações, consiste em cinco camadas convolucionais (com 16, 32, 32, 32 e 32 canais), ativações ReLU entre elas, e uma camada totalmente conectada no final produzindo Q-values para cada ação. O treinamento foi feito em AWS com 2.000 episódios, usando epsilon-greedy para balancear exploração e exploração.
Deng testou duas variantes que diferem na função de recompensa: DQN com recompensa instantânea (a pontuação obtida imediatamente após a jogada) e DQN com recompensa Monte Carlo (uma estimativa da pontuação esperada, computada como média sobre futuras configurações aleatórias).
A observação técnica mais interessante do paper é que a variante Monte Carlo na verdade não faz sentido matemático no contexto de Q-learning. Q-learning assume a equação de Bellman, que pressupõe que a recompensa é causada pela ação específica tomada no estado específico, levando a um novo estado específico. A recompensa Monte Carlo é uma estimativa aleatória dessa recompensa instantânea, o que introduz um viés estatístico no aprendizado da função de valor. Essa observação é um bom exemplo do tipo de erro sutil que aparece quando alguém aplica algoritmos conhecidos sem validar as suposições teóricas que eles exigem.
Os resultados finais de Deng são comparáveis e, em alguns aspectos, superam MCTS no ambiente simplificado. Random pick produziu 157 pontos médios em 40 movimentos, MCTS produziu 325 pontos, e DQN com recompensa instantânea produziu 370 pontos. Em testes contra um jogador humano, o DQN ficou “um pouco pior” nas palavras do autor, mas bastante próximo. O código está disponível publicamente em github.com/baolidakai/candy_crush_ai.
Há uma distinção filosófica importante entre os trabalhos de Deng e os da King. Deng treinou um agente para maximizar pontuação, seguindo o paradigma clássico de reinforcement learning. A King treinou um agente para imitar comportamento humano, usando aprendizado supervisionado. Os dois agentes resolvem o jogo, mas servem a propósitos completamente diferentes.
A sutileza do “human-like” versus “optimal”
Esse contraste é o ponto mais interessante do design da King, e o que mais acho que vale extrair como lição de engenharia.
A intuição natural de alguém começando em machine learning aplicado a jogos é treinar um agente para jogar o melhor possível. Faz sentido para um jogo como xadrez ou Go, onde o objetivo é ganhar. Mas para estimar dificuldade humana, um agente ótimo é inútil. Um bot que sempre encontra a melhor jogada acharia qualquer nível trivial, porque com jogadas ótimas quase todos os níveis são solucionáveis dentro do orçamento de movimentos disponível. A dificuldade percebida por humanos não vem da dificuldade intrínseca do nível em sentido ótimo, vem da distância entre o comportamento humano típico e o comportamento ótimo naquele nível específico.
O que a King queria era um agente cuja distribuição de resultados espelhasse a distribuição de resultados humanos. Isso significa um agente que cometa o tipo certo de erro, nas proporções certas. O aprendizado supervisionado em cima de decisões humanas reais captura exatamente isso. A rede neural não está aprendendo estratégia ótima, está aprendendo a distribuição empírica de comportamento humano.
Um trabalho relacionado que vale mencionar é “Winning Isn’t Everything: Training Human-Like Agents for Playtesting”, publicado por pesquisadores da Electronic Arts. O título do paper é essencialmente uma declaração de design: em playtesting automatizado, o objetivo não pode ser vencer, precisa ser reproduzir a experiência de quem vai jogar.
A Universidade Roma Tre também publicou em 2020 um sistema chamado JellyGym, aplicando deep reinforcement learning à classe geral de jogos match-3. A arquitetura usa uma rede com camada oculta de 100 neurônios totalmente conectada, seguida por outra de 200 neurônios, e uma camada de saída com 324 neurônios, um para cada swap possível (incluindo swaps proibidos). O treinamento foi feito em GPU Tesla V100. Os autores compararam quatro jogadores: Random Player (ações com probabilidade fixa), JellyGym (melhor ação segundo o modelo), Smart Player (melhor tipo de Jolly) e Real Users. A comparação explícita com usuários reais, novamente, reforça o ponto de que o benchmark relevante é comportamento humano.
Esse framing é transferível para outros contextos. Em qualquer problema de simulação ou estimativa baseada em comportamento, a pergunta inicial precisa ser: estou tentando modelar o ótimo ou o real. São objetivos diferentes, exigem datasets diferentes, funções de perda diferentes, e produzem modelos com propriedades completamente distintas.
BAIT e a camada de QA visual
Além do sistema de estimativa de dificuldade, a King construiu uma ferramenta complementar chamada BAIT (Bot for AI Testing), documentada em um artigo do InfoQ por Alexander Andelkovic em 2019.
O BAIT já percorreu mais de 4.500 níveis automaticamente, detectando problemas que são tediosos para QA humano: texturas ausentes, strings de texto faltando (onde o ID da string aparece no lugar do texto traduzido), elementos gráficos sobrepostos, e artefatos de renderização em diferentes resoluções e orientações de celular. Para a detecção visual automatizada, usa uma combinação de algoritmos de similaridade de contorno e a Google Vision API.
Essa parte da história é um lembrete de que em operações reais de IA, o modelo central é frequentemente uma peça entre várias.
A estimativa de dificuldade resolve uma categoria de problema. O QA visual automatizado resolve outra. Juntos, eles liberam ciclos humanos para trabalho criativo que realmente exige julgamento humano.
Três lições para projetos de IA em empresas
Saindo do contexto específico de Candy Crush, há três princípios que aparecem no caso da King e que aplico mentalmente quando olho para projetos de IA em organizações.
Lição 1: Definição operacional do objetivo
O maior erro recorrente em projetos de IA aplicada é começar com um objetivo vago. “Melhorar experiência do cliente”, “otimizar processo comercial”, “acelerar decisão”. Esses objetivos não são treináveis. Um modelo precisa de uma função de perda, e uma função de perda precisa de uma métrica operacional clara.
A King não treinou um modelo para “melhorar dificuldade dos níveis”. Treinou um modelo para prever AHSR com erro absoluto médio abaixo de um limiar específico. A tradução de um objetivo de negócio para uma métrica operacional é onde a maior parte do valor de um projeto de IA é criada ou destruída. E essa tradução quase sempre exige discussões repetidas entre o time de produto e o time técnico, porque as primeiras versões costumam estar erradas.
O contraste entre King (supervised learning) e Deng (reinforcement learning) ilustra bem o ponto. Os dois começaram do mesmo jogo, mas tinham objetivos operacionais diferentes. Deng queria maximizar score, King queria prever comportamento humano. Os modelos resultantes são incomparáveis não porque uma abordagem é melhor, mas porque resolvem problemas diferentes.
Lição 2: O problema real está nos dados, não no modelo
Philipp Eisen, engenheiro de machine learning na King, fez uma observação que sintetiza bem a realidade: a maior parte do tempo em um projeto de ML não é gasto ajustando modelos, é gasto colocando dados no formato certo, limpando, rotulando, transformando. Alex Nodet, também da King, em entrevista ao Computer Weekly em 2019, fez uma observação complementar: “Ter um modelo de ML treinado e aprendendo é apenas metade do trabalho.” A outra metade é colocá-lo em produção de forma confiável, monitorada, com dados chegando no formato esperado.

Essa afirmação é repetida à exaustão em conferências de data science, e ainda assim é sistematicamente subestimada em orçamentos de projeto. Equipes planejam projetos de IA como se fossem 70% modelagem e 30% dados. A realidade costuma ser o inverso.
O caso da King é particularmente ilustrativo porque os 12 milhões de pares estado-ação não apareceram magicamente. Eles são o resultado de anos de instrumentação cuidadosa da telemetria de jogo, decisões sobre o que armazenar, arquitetura de pipelines que levam dados de dispositivos móveis para sistemas de treinamento, e infraestrutura para manter tudo isso em produção. A King usa Google Cloud com Pub/Sub como middleware para o loop de feedback entre simulações e módulos de análise.
No meu trabalho no GRI Institute, onde lidero um data lake consolidando 13 fontes em BigQuery e Redshift, isso se confirma todos os dias. A parte mais cara do pipeline não são os modelos, são os ETLs, a reconciliação de identificadores, a limpeza de inconsistências, a construção de taxonomia canônica, a rotulagem semântica. Os modelos vêm depois, e costumam ser a parte simples.
Velocidade de iteração é o que muda o jogo
O ganho econômico real da King não foi ter um modelo mais preciso. Foi reduzir o ciclo de feedback de calibração de níveis de sete dias para menos de um minuto. Essa mudança de ordem de magnitude no tempo de iteração altera completamente a economia do design.
Quando o custo de testar uma hipótese cai drasticamente, o comportamento racional muda. Em vez de preparar cuidadosamente uma hipótese antes de testar, você testa muitas hipóteses em paralelo e usa os dados para decidir quais aprofundar. Isso é o princípio que está por trás de fenômenos como A/B testing em massa em produtos digitais, e é o mesmo princípio que permite à King manter o ritmo de lançamento de 15 níveis por semana.
Ao avaliar projetos de IA candidatos em uma empresa, uma boa pergunta estratégica é: que ciclo de aprendizado atualmente leva semanas e poderia ser reduzido para minutos. Esse tipo de projeto geralmente tem retorno superior a projetos que prometem apenas mais precisão em uma decisão que já é tomada rapidamente.
Por que comparar as três abordagens importa
As três abordagens publicadas (MCTS de Poromaa, CNN supervisionada da King, DQN de Deng) são tecnicamente interessantes por si só, mas comparadas elas ensinam algo mais geral sobre como escolher um método de machine learning para um problema real.
MCTS é apropriado quando você tem um simulador do ambiente e quer encontrar boas jogadas, sem precisar de dados de treinamento. É computacionalmente caro em inferência, e não aprende entre episódios.
DQN é apropriado quando você quer aprender uma política ótima a partir de recompensa escalar, e tem recursos para rodar muitos episódios de treinamento. Aprende uma política genérica, mas não necessariamente uma política humana.
Supervised learning em cima de dados comportamentais é apropriado quando você tem acesso a decisões humanas em escala e quer reproduzir distribuição de comportamento, não estratégia ótima. É barato em inferência, mas depende criticamente da qualidade e volume dos dados.
A escolha entre os três não é técnica em primeiro lugar, é uma escolha sobre qual problema você está resolvendo. E essa decisão precisa vir antes da arquitetura.
O caso Candy Crush é um dos exemplos mais bem documentados de IA aplicada a um problema de produto real, em escala industrial, com dados de telemetria massivos, e com alternativas acadêmicas bem documentadas para comparação. Para quem trabalha com dados ou IA em empresas, os detalhes são instrutivos.
Referências
Para quem quiser se aprofundar tecnicamente, as fontes principais são:
Gudmundsson, S., Eisen, P., Poromaa, E., Nodet, A., Purmonen, S., Kozakowski, B., Meurling, R., Cao, L. “Human-Like Playtesting with Deep Learning”. IEEE Conference on Computational Intelligence and Games, 2018. O paper da própria King descrevendo a arquitetura CNN em produção.
Deng, B. “Learn to play Candy Crush”. Stanford CS230 Deep Learning, Winter 2020. Abordagem via Deep Q-Network com código aberto em github.com/baolidakai/candy_crush_ai.
Poromaa, E. R. “Crushing Candy Crush: Predicting Human Success Rate in a Mobile Game using Monte-Carlo Tree Search”. Master’s thesis, KTH Royal Institute of Technology, 2017.
Purmonen, S. “Predicting Game Level Difficulty Using Deep Neural Networks”. Master’s thesis, KTH Royal Institute of Technology, 2017.
Walsh, T. “Candy Crush is NP-hard”. arXiv:1403.1911, 2014.
Andelkovic, A. “How King uses AI to test Candy Crush Saga”. InfoQ, 2019.
Zhao, Y., Borovikov, I., Beirami, A., et al. “Winning Isn’t Everything: Training Human-Like Agents for Playtesting”. Electronic Arts / NeurIPS, 2020.
“Testing match-3 video games with Deep Reinforcement Learning”. arXiv:2007.01137, 2020. Universidade Roma Tre.