

Data Architecture para Analytics e AI: Quando a Escolha Arquitetural Define o Destino Competitivo
O Trator Inteligente que Processa 15 Mil Medições por Segundo

Em 2023, John May, CEO da John Deere, fez algo inédito na história do Consumer Electronics Show: uma fabricante de tratores apresentou o keynote de abertura. A razão estava nos números que sustentavam a transformação da empresa. Um único trator modelo 8RX com plantadora de 24 linhas carrega mais de 300 sensores IoT e 140 controladores, processando 15 mil medições por segundo durante a operação. Entre 2021 e 2024, a frota conectada da empresa saltou de 440 mil para 750 mil máquinas, um crescimento de 70%, enquanto a área engajada expandiu de 315 milhões para 468 milhões de acres.
Mas o que transforma essa avalanche de dados em vantagem competitiva não são os sensores individuais, e sim a arquitetura que os conecta. O sistema ExactShot, por exemplo, reduziu o uso de fertilizantes em 60%, gerando economia estimada de 650 milhões de dólares anuais apenas no mercado americano. Essa economia não surgiu de algoritmos mais sofisticados ou modelos de machine learning mais precisos. Nasceu de uma decisão arquitetural fundamental: integrar dados de campo, clima, preços de commodities, condições de solo e histórico de colheitas em uma plataforma unificada que alimenta simultaneamente operações de campo e decisões de negócio.
A transformação da John Deere ilustra uma verdade frequentemente negligenciada: em data architecture para analytics e AI, a escolha do padrão arquitetural frequentemente importa mais que a sofisticação dos modelos. Uma arquitetura inadequada pode tornar irrelevante o algoritmo mais brilhante, enquanto uma arquitetura bem desenhada pode extrair valor extraordinário de técnicas relativamente simples.

O Dilema Arquitetural: Não Existe Solução Universal
A tentação de prescrever uma única arquitetura como solução definitiva ignora uma realidade incômoda: contextos diferentes demandam abordagens diferentes, e o que funciona magnificamente para uma empresa pode representar desperdício monumental para outra.

Considere três cenários reais que ilustram essa diversidade.
O Spotify processa aproximadamente 4 terabytes de dados de usuários diariamente, distribuídos em 28 petabytes de armazenamento global. Sua arquitetura evoluiu de pipelines Python com Luigi e Hadoop MapReduce para Scalding (a biblioteca Scala do Twitter), depois Apache Spark para machine learning, e finalmente para uma combinação de Apache Beam via Scio com Google BigQuery para consultas ad-hoc. A feature “Discover Weekly”, que conquistou mais de 2,3 bilhões de horas de reprodução nos primeiros cinco anos, roda sobre Scalding, não sobre a tecnologia mais recente disponível.
A Netflix, por sua vez, desenvolveu o que chama internamente de “Data Mesh”, uma plataforma que combina Apache Kafka para transporte, Apache Flink para processamento em tempo real, Apache Iceberg para gerenciamento de tabelas analíticas, e Apache Avro como schema padrão entre domínios. A descentralização da propriedade dos dados, distribuída entre equipes de recomendação de conteúdo, engajamento de usuários e performance de plataforma, eliminou gargalos que antes atrasavam projetos de dados em semanas.
Já a Starbucks construiu o Deep Brew, sua plataforma proprietária de AI lançada em 2019, sobre uma fundação completamente diferente: o Enterprise Data Analytics Platform (EDAP) alimentado por um data lake que unifica dados de transações, geolocalização, clima, inventário e comportamento de clientes. Com 100 milhões de transações semanais globalmente, a empresa reporta que a adoção de AI gerou incremento de 30% no ROI de marketing e crescimento de 15% no engajamento de clientes.
Três empresas extraordinariamente bem-sucedidas em analytics e AI, três arquiteturas fundamentalmente diferentes. O denominador comum não está na tecnologia escolhida, mas na adequação entre arquitetura e necessidades específicas do negócio.
Data Lakehouse: A Convergência que Redefiniu as Possibilidades

Durante anos, organizações enfrentaram uma escolha binária: data warehouses para consultas estruturadas e alta performance analítica, ou data lakes para flexibilidade e armazenamento de dados não estruturados a baixo custo. Essa dicotomia forçava trade-offs dolorosos, resultando frequentemente em arquiteturas híbridas complexas onde dados transitavam entre sistemas, multiplicando custos operacionais e introduzindo latências que comprometiam casos de uso em tempo real.
O conceito de data lakehouse emergiu como uma tentativa de transcender essa divisão. A arquitetura combina a escalabilidade e economia do armazenamento em data lakes com as garantias transacionais ACID (Atomicidade, Consistência, Isolamento, Durabilidade) e performance de consulta tradicionalmente associadas a data warehouses. Tecnologias como Delta Lake, Apache Iceberg e Apache Hudi implementam esse paradigma através de formatos de tabela abertos que adicionam camadas de metadados sobre armazenamento de objetos commodity.
No setor de saúde, estudos recentes documentam resultados expressivos. Uma análise publicada pelo IEEE demonstrou que implementações de data lakehouse em organizações de saúde alcançaram redução de 42% no tempo de recuperação de dados, melhoria de 35% em outcomes de pacientes, e redução de 28% no tempo de diagnóstico. A capacidade de processar simultaneamente dados estruturados de prontuários eletrônicos, imagens médicas não estruturadas (DICOM), e streams de dispositivos IoT de monitoramento contínuo cria possibilidades que arquiteturas anteriores simplesmente não suportavam.
O Gartner prevê que, até 2026, organizações com plataformas unificadas de Data e AI (Lakehouses) implantarão aplicações de Inteligência Artificial 70% mais rápido do que aquelas com arquiteturas fragmentadas. A Netflix utiliza Apache Iceberg extensivamente como sink para pipelines do Data Mesh, permitindo que dados operacionais fluam continuamente para tabelas analíticas consultáveis via SQL padrão, eliminando a necessidade de processos ETL batch que antes atrasavam insights em horas ou dias.
Mas a arquitetura lakehouse não representa panaceia universal. Organizações com workloads predominantemente transacionais e requisitos de latência de milissegundos podem encontrar overhead desnecessário. Empresas com dados majoritariamente estruturados e padrões de consulta previsíveis podem extrair melhor custo-benefício de data warehouses tradicionais otimizados para seus casos de uso específicos.
Data Mesh: Descentralização como Estratégia Arquitetural

A abordagem de data mesh representa menos uma tecnologia específica e mais uma filosofia organizacional aplicada à arquitetura de dados. Proposta por Zhamak Dehghani da ThoughtWorks, a arquitetura advoga pela descentralização da propriedade de dados para equipes de domínio, tratamento de dados como produtos com SLAs definidos, infraestrutura self-service, e governança federada.
A implementação da Netflix ilustra como princípios abstratos se traduzem em arquitetura concreta. O sistema divide-se em dois planos: o control plane (Data Mesh Controller) que recebe requisições de usuários, orquestra pipelines e calcula configurações; e o data plane (Data Mesh Pipeline) que executa as operações efetivas de movimento e processamento de dados. Conectores monitoram fontes de dados e produzem eventos de Change Data Capture (CDC), Apache Kafka atua como transportador central, e processadores implementados como jobs Apache Flink aplicam transformações como filtro, projeção, união e join.
O impacto organizacional pode ser tão significativo quanto o técnico. A descentralização elimina o gargalo do “time central de dados” que tradicionalmente se torna bottleneck em organizações data-intensive. Equipes de domínio, mais próximas dos dados e seus contextos de negócio, conseguem garantir maior qualidade e relevância. O Data Mesh da Netflix processa dados de múltiplas fontes incluindo MySQL, Postgres, e CockroachDB, enriquecendo-os via GraphQL queries ao Studio Edge antes de sincronizá-los para Iceberg tables no data warehouse.
Porém, data mesh introduz complexidades próprias. A governança federada requer maturidade organizacional para funcionar, pois sem clareza sobre padrões e responsabilidades, a descentralização pode degenerar em silos fragmentados. O investimento em plataforma self-service é substancial, sendo que a promessa de democratização só se materializa quando a infraestrutura subjacente atinge níveis elevados de automação e usabilidade. Organizações menores ou com dados menos diversificados podem encontrar overhead desproporcional aos benefícios.
Medallion Architecture: Zonas de Maturidade de Dados
O padrão Medallion, popularizado pelo Databricks, organiza dados em três camadas progressivas. A camada bronze ingere dados raw diretamente das fontes, preservando formato original e histórico completo. A camada silver aplica limpeza, validação, conformação e deduplicação, produzindo dados “conformed” mas ainda granulares. A camada gold agrega e modela dados para casos de uso específicos, otimizando para consumo por ferramentas de BI, dashboards executivos, ou features para modelos de machine learning.

A elegância do padrão reside na separação clara de responsabilidades e na rastreabilidade end-to-end. Qualquer anomalia detectada na camada gold pode ser investigada regressando às camadas anteriores, com cada transformação documentada e auditável. Para organizações em setores regulados (saúde, finanças, governo), essa rastreabilidade frequentemente constitui requisito não-negociável.
John Deere implementa variações desse padrão para integrar dados de 750 mil máquinas conectadas com informações de clima, preços de commodities, e histórico agronômico. A camada bronze captura telemetria raw dos sensores a taxas de milhares de medições por segundo. A camada silver normaliza formatos, aplica correções de drift de sensores, e correlaciona temporalmente dados de diferentes fontes. A camada gold produz as “prescrições” acionáveis que guiam decisões de plantio, irrigação e colheita, informando cada semente, gota de fertilizante e movimento do trator.
O padrão medallion não exclui outras abordagens. Organizações frequentemente implementam camadas bronze/silver/gold dentro de um lakehouse, ou distribuem a responsabilidade por diferentes zonas entre equipes de domínio em um data mesh. A arquitetura medallion fornece um framework mental para organizar transformações progressivas, independente da tecnologia específica que as implementa.
Real-Time vs. Batch: O Espectro de Latência
Uma das decisões arquiteturais mais impactantes envolve o espectro entre processamento batch e streaming em tempo real. A resposta correta depende fundamentalmente do valor de negócio associado à redução de latência, e esse valor varia dramaticamente entre casos de uso.
O Spotify processa a maioria das features de personalização via batch, retreinando modelos diariamente com dados de interação coletados. O algoritmo BaRT (Bayesian Additive Regression Trees) que personaliza a home screen é otimizado para streams com mais de 30 segundos, ignorando reproduções mais curtas. A latência de um dia entre comportamento do usuário e atualização de recomendações é perfeitamente aceitável para esse caso de uso, e o processamento batch permite otimizações de custo e simplicidade operacional impossíveis em arquiteturas puramente streaming.
Contraste isso com o sistema “See and Spray” da John Deere, que utiliza 97 robôs com computer vision para identificar e pulverizar ervas daninhas individualmente, reduzindo uso de herbicidas em 80-90%. A latência máxima tolerável aqui é de milissegundos, já que o trator continua se movendo enquanto o sistema processa cada planta. Qualquer arquitetura que introduzisse latência de segundos tornaria o sistema inútil para seu propósito.
A Starbucks opera em múltiplos pontos do espectro simultaneamente. Recomendações personalizadas no app utilizam dados históricos agregados, tolerando latência de horas. Painéis de drive-thru atualizam sugestões com base em clima atual e inventário local, requerendo atualizações em minutos. Promoções geo-localizadas disparam notificações push quando clientes se aproximam de lojas, demandando processamento em tempo real.
A arquitetura Lambda, que paraleliza pipelines batch e streaming mesclando resultados, oferece uma abordagem híbrida, porém introduz complexidade de manter lógica duplicada em dois sistemas distintos. A arquitetura Kappa simplifica usando apenas streaming, mas pode resultar em custos elevados para workloads predominantemente históricos. Apache Beam e frameworks similares permitem expressar pipelines uma única vez executando-os em batch ou streaming conforme necessidade, reduzindo duplicação às custas de abstrações adicionais.
Governança e Qualidade: O Alicerce Invisível
Arquiteturas tecnicamente elegantes colapsam sem fundamentos sólidos de governança e qualidade de dados. O conceito de “data swamp” (pântano de dados), onde data lakes degeneram em repositórios caóticos de dados não catalogados e não confiáveis, tornou-se emblema dos perigos de negligenciar governança.
O Netflix aborda isso através de schemas fortemente tipados usando Apache Avro como padrão entre domínios. A plataforma valida compatibilidade de schemas automaticamente e tenta evoluir pipelines consumidores sem intervenção humana quando schemas mudam na origem. Um catálogo de dados centralizado fornece descobribilidade e visibilidade, permitindo que equipes encontrem e entendam dados disponíveis antes de consumí-los.
A John Deere enfrenta desafios únicos de governança relacionados à propriedade dos dados agrícolas. Agricultores expressam preocupações sobre compartilhar informações que poderiam beneficiar concorrentes ou influenciar regulações. A arquitetura precisa suportar controles granulares de acesso e políticas configuráveis de compartilhamento, sem comprometer a capacidade de agregar insights entre fazendas para melhorar modelos preditivos.
Healthcare lakehouses demonstram os requisitos mais estritos de governança. Conformidade com HIPAA demanda proteção automatizada de PHI (Protected Health Information), técnicas de preservação de privacidade, e auditoria completa de acessos. A arquitetura deve implementar esses controles como primitivas de primeira classe, não como adições posteriores, pois retrofitar segurança e conformidade em arquiteturas existentes invariavelmente resulta em gaps e vulnerabilidades.
Feature Stores: A Ponte Entre Dados e Modelos
Uma evolução arquitetural significativa envolve feature stores, repositórios especializados para features de machine learning que suportam tanto treinamento offline quanto inferência online. A motivação é pragmática: organizações descobriram que equipes de data science frequentemente reimplementam as mesmas transformações de features, introduzindo inconsistências sutis entre treinamento e produção que degradam performance de modelos.
O Deep Brew da Starbucks exemplifica a integração entre data platform e feature engineering. O sistema extrai features de múltiplas fontes (transações, geolocalização, clima, inventário) e as disponibiliza consistentemente para diversos modelos de personalização, previsão de demanda, e otimização de workforce. A mesma feature “hora desde última visita do cliente” alimenta tanto o modelo que treina offline quanto o sistema que gera recomendações em tempo real no app.
Feature stores introduzem uma camada de abstração entre raw data e modelos de ML. Isso permite que cientistas de dados trabalhem em vocabulário de features de negócio (recência de compra, frequência de visitas, preferências sazonais) enquanto a plataforma gerencia complexidades de materialização, versionamento e sincronização. O trade-off é adicionar mais um componente à stack, aumentando overhead operacional para organizações com poucos modelos em produção.
Decisões Estratégicas: Quando Cada Arquitetura Faz Sentido
A escolha arquitetural ótima emerge da interseção entre requisitos técnicos e contexto organizacional.
Data warehouse tradicional permanece adequado quando:
Dados são predominantemente estruturados e relacionais
Padrões de consulta são previsíveis e bem definidos
Performance de query é prioridade máxima
Equipe possui expertise consolidada em SQL e modelagem dimensional
Volume de dados é significativo mas não extremo
Data lake faz sentido quando:
Diversidade de tipos de dados (estruturados, semi-estruturados, não estruturados) é alta
Casos de uso futuros são incertos, demandando flexibilidade
Custo de armazenamento é fator crítico
Data science/ML representam casos de uso primários
Schema evolution é frequente e imprevisível
Lakehouse torna-se atraente quando:
Organização precisa suportar tanto BI tradicional quanto ML avançado
Complexidade de manter arquiteturas separadas gera overhead inaceitável
Requisitos incluem tanto análise histórica quanto processamento streaming
Equipe possui maturidade para adotar tecnologias relativamente recentes
Volume e diversidade de dados justificam investimento em plataforma unificada
Data mesh justifica-se quando:
Organização é grande com múltiplos domínios de negócio distintos
Time central de dados tornou-se gargalo que atrasa projetos
Equipes de domínio possuem maturidade técnica para assumir ownership
Investimento em plataforma self-service é viável
Governança federada pode ser implementada efetivamente
Implementação Pragmática: O Caminho da Evolução
Raramente organizações implementam arquiteturas de dados greenfield. A realidade típica envolve sistemas legados que não podem ser substituídos abruptamente, equipes com skillsets existentes que precisam evoluir gradualmente, e orçamentos que demandam demonstração incremental de valor.
Uma abordagem pragmática começa identificando um domínio de negócio com alto potencial de impacto e complexidade gerenciável. O piloto implementa a nova arquitetura para esse domínio específico, demonstrando valor tangível enquanto a equipe desenvolve expertise. Sucessos iniciais justificam expansão gradual, com aprendizados do piloto informando refinamentos antes de escalar.
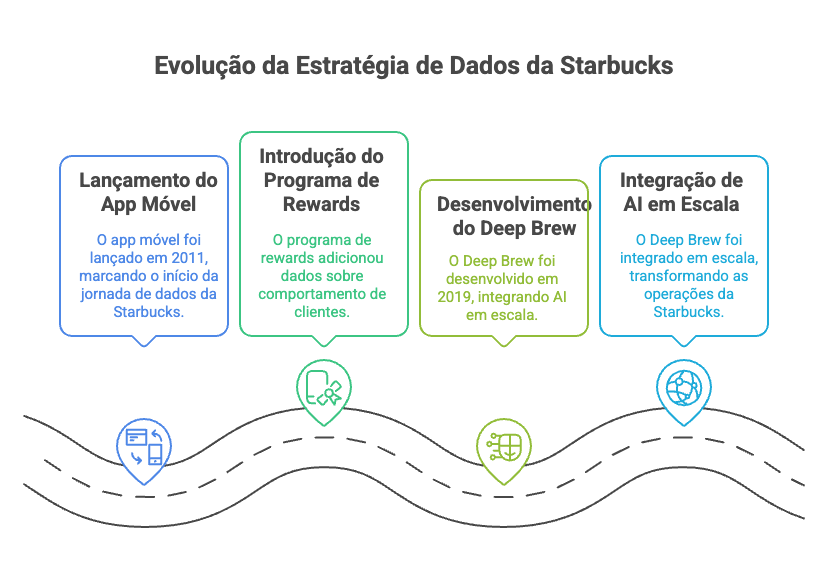
A Starbucks seguiu essa trajetória. O app móvel lançado em 2011 marcou o ponto de entrada em data e analytics. O programa de rewards adicionou camadas de dados sobre comportamento de clientes. Somente em 2019, com fundações estabelecidas, veio o Deep Brew integrando AI em escala. A transformação levou quase uma década de evolução incremental, não um big bang arquitetural, conforme ilustrado na imagem abaixo.
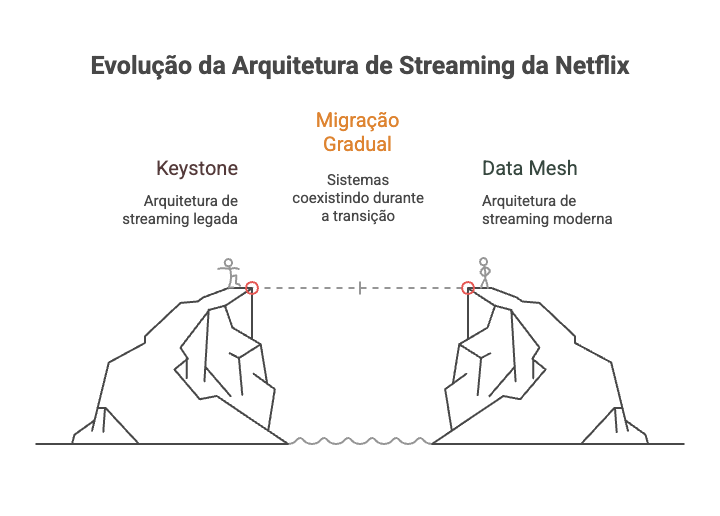
Netflix documenta sua própria evolução de Keystone (geração anterior de streaming pipelines) para Data Mesh, motivada por casos de uso emergentes que a arquitetura existente não suportava adequadamente. A migração ocorreu gradualmente, com sistemas coexistindo enquanto novos casos de uso migravam para a nova plataforma.
O Fator Humano: Arquitetura é Decisão Organizacional
Arquiteturas de dados não existem em vácuo técnico. Elas refletem e reforçam estruturas organizacionais, competências de equipes, e culturas empresariais. A Lei de Conway (organizações produzem sistemas que espelham suas estruturas de comunicação) aplica-se plenamente a data architecture.
Uma organização centralizada com equipe de dados pequena mas experiente pode extrair valor máximo de um data warehouse bem gerenciado. Tentar implementar data mesh nesse contexto criaria overhead sem benefício proporcional. Inversamente, uma organização descentralizada com múltiplas equipes de produto autônomas pode encontrar no data mesh um padrão que se alinha naturalmente com sua cultura de ownership distribuída.
O CTO que seleciona arquitetura puramente por mérito técnico, ignorando maturidade organizacional e dinâmicas de equipes, frequentemente observa implementações tecnicamente corretas que falham em gerar valor de negócio. A arquitetura mais sofisticada do mundo permanece inútil se a organização não consegue operá-la efetivamente.
Considerações Finais: O Destino Está na Arquitetura
A transformação da John Deere de fabricante de tratores para empresa de tecnologia agrícola, com máquinas processando 15 mil medições por segundo e gerando economias de centenas de milhões de dólares, não resultou primariamente de avanços em machine learning ou sensores mais precisos. Resultou de decisões arquiteturais que permitiram integrar dados de múltiplas fontes em insights acionáveis entregues no momento e local onde geram valor.
Da mesma forma, os 2,3 bilhões de horas de reprodução do Discover Weekly do Spotify, os 100 milhões de transações semanais processadas pelo Deep Brew da Starbucks, e a eliminação de gargalos de dados na Netflix via Data Mesh representam triunfos arquiteturais tanto quanto algorítmicos.
Para CTOs e Enterprise Architects navegando decisões sobre data architecture para analytics e AI, a mensagem central é de humildade pragmática.
Não existe arquitetura universalmente superior. Existe a arquitetura que melhor serve necessidades específicas do negócio, se alinha com capacidades organizacionais existentes, e evolui conforme requisitos mudam.
As organizações mais bem-sucedidas não escolhem a tecnologia mais recente ou mais hyped. Escolhem a arquitetura que transforma seus dados específicos em sua vantagem competitiva específica.A escolha arquitetural define o destino competitivo. Mas essa escolha só pode ser feita efetivamente por quem compreende profundamente tanto as possibilidades técnicas quanto as realidades do negócio que a arquitetura deve servir.