

Data Pipelines e ETL para Business Intelligence: Transformando Dados em Decisões Estratégicas
- Guilherme Favaron
- há 2 dias
- 13 min de leitura

Guia técnico sobre data pipelines e ETL para business intelligence: arquiteturas modernas, processamento em tempo real, otimização de performance e integração analítica.
Arquiteturas Modernas Para Análise de Dados em Tempo Real
Quando uma empresa parceira me procurou com o desafio de unificar dados dispersos em mais de 12 sistemas diferentes para criar dashboards executivos que realmente impactassem tomadas de decisão, descobri que o problema ia muito além de simplesmente "conectar bases de dados". A organização estava perdendo oportunidades de mercado porque insights críticos levavam semanas para chegar aos tomadores de decisão, relatórios mensais continham inconsistências que geravam desconfiança, e analistas gastavam 70% do tempo coletando dados ao invés de analisá-los.
Após implementar uma arquitetura moderna de data pipelines que combina processamento em tempo real com ETL otimizado para business intelligence, conseguimos reduzir o time-to-insight de 3 semanas para 4 horas, aumentar a confiabilidade dos dados em 95% através de validações automatizadas, e liberar 60% do tempo dos analistas para atividades de alto valor agregado que resultaram em 23% de melhoria na precisão das previsões de demanda.
Este artigo explora como projetar data pipelines que realmente servem às necessidades de business intelligence, transcendendo limitações de ETL tradicional para criar sistemas que habilitam organizações realmente orientadas por dados.
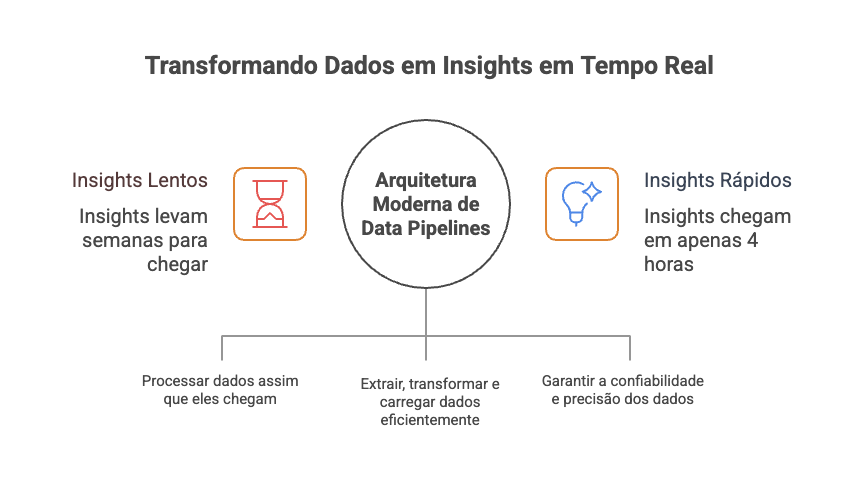
O gap entre dados e decisões

Limitações do ETL tradicional
O primeiro obstáculo que identifiquei foi que processos ETL convencionais foram projetados para uma era onde análises aconteciam em ciclos mensais ou semanais, com tolerância para latência de horas ou dias. No ambiente de negócios atual, onde vantagem competitiva frequentemente depende de responder rapidamente a mudanças de mercado, essa latência é inaceitável.
Sistemas ETL tradicionais também operam com pressupostos sobre qualidade e estrutura de dados que raramente se sustentam na realidade. Dados chegam incompletos, com formatos inconsistentes, ou contêm outliers que podem distorcer análises se não forem tratados adequadamente. A abordagem batch tradicional torna difícil detectar e corrigir esses problemas rapidamente.
A experiência com a empresa parceira revelou que 40% dos relatórios continham dados defasados ou incorretos, não por falhas técnicas, mas porque os processos ETL não foram projetados para lidar com a complexidade e velocidade dos dados empresariais modernos.
Necessidades modernas de business intelligence
Business intelligence hoje exige muito mais que relatórios estáticos baseados em dados históricos. Stakeholders precisam de insights dinâmicos que se atualizam conforme novos dados chegam, capacidade de drill-down em tempo real para investigar anomalias, e integração com sistemas operacionais que permite ação baseada em insights.
Esta evolução nas expectativas requer repensar fundamentalmente como dados fluem desde as fontes até os tomadores de decisão. A arquitetura precisa suportar não apenas volume e velocidade crescentes, mas também variedade de tipos de dados e variabilidade nas necessidades de análise.
Para a empresa parceira, isso significou desenvolver pipelines que pudessem processar dados transacionais em tempo real, integrar informações de inteligência de mercado externas, e servir tanto dashboards executivos quanto análises ad-hoc de analistas especializados.
Arquitetura moderna de data pipelines
Arquitetura de processamento orientada por eventos
A base da solução implementada baseia-se em arquitetura orientada por eventos que processa dados conforme eles chegam, ao invés de aguardar janelas batch predefinidas. Esta abordagem permite latência drasticamente reduzida para insights críticos enquanto mantém eficiência para processamento de alto volume.
O design utiliza filas de mensagem e stream processing para lidar com diferentes tipos de dados com requisitos distintos. Transações financeiras críticas são processadas em sub-segundo, enquanto dados de análise histórica podem seguir caminhos otimizados para throughput ao invés de latência.
Esta flexibilidade arquitetural permite que o mesmo sistema sirva necessidades tanto de monitoramento em tempo real quanto de processamento analítico profundo, eliminando a necessidade de manter múltiplos sistemas separados com overhead associado.
Gates de qualidade de dados integrados
Uma das inovações mais impactantes foi implementar validação de qualidade de dados como parte integral do pipeline, não como etapa separada. Cada estágio do processamento inclui verificações automatizadas que detectam inconsistências, validam regras de negócio, e sinalizam potenciais problemas antes que dados cheguem aos sistemas analíticos.
Estes gates de qualidade operam em múltiplos níveis, desde validação básica de tipos de dados até lógica complexa de negócio que garante que dados façam sentido no contexto organizacional. Por exemplo, valores de receita que excedem limites plausíveis disparam processos automáticos de revisão, enquanto dados faltantes são tratados através de imputação inteligente ou sinalização explícita para atenção do analista.
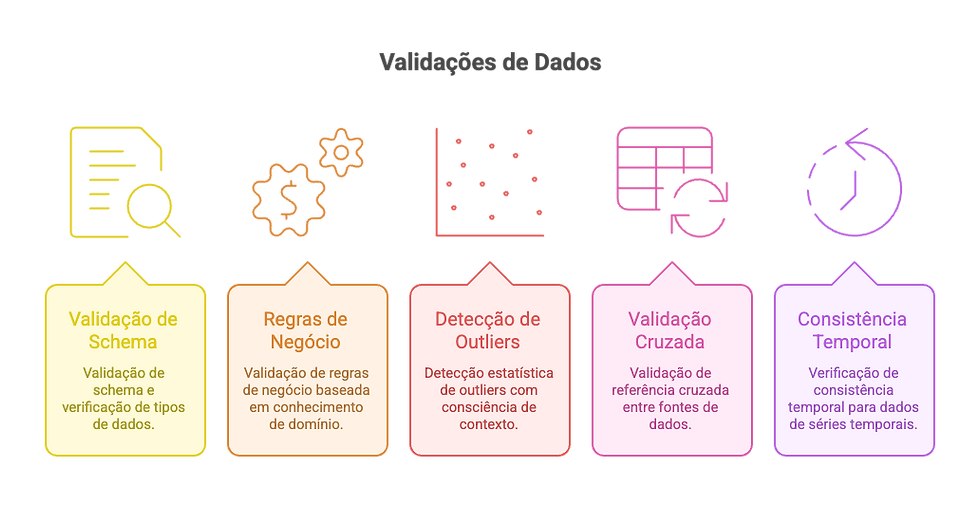
Camadas de validação de qualidade implementadas:
Validação de schema e verificação de tipos de dados
Validação de regras de negócio baseada em conhecimento de domínio
Detecção estatística de outliers com consciência de contexto
Validação de referência cruzada entre fontes de dados
Verificação de consistência temporal para dados de séries temporais
Auto-recuperação e recuperação de erros
Data pipelines de produção enfrentam falhas inevitáveis devido a problemas de rede, interrupções de sistemas de origem, ou corrupção de dados. A arquitetura desenvolvida inclui mecanismos abrangentes de recuperação de erros que minimizam perda de dados e garantem continuidade de negócio.
O sistema detecta falhas automaticamente e tenta recuperação através de múltiplas estratégias. Problemas temporários de rede disparam lógica de retry com backoff exponencial, dados corrompidos são colocados em quarentena para revisão manual, e interrupções de sistemas de origem ativam fontes de dados de fallback onde disponíveis.
Crítico para continuidade de negócio é a capacidade de replay de processamento de dados de qualquer ponto no tempo, garantindo que falhas temporárias não resultem em perda permanente de dados ou lacunas de análise que impactem decisões de negócio.
Estratégias de implementação
Trade-offs entre batch e streaming
Uma das decisões mais importantes no design de pipeline é determinar quando usar processamento batch versus abordagens streaming. Cada abordagem tem vantagens específicas que se adequam a diferentes requisitos de negócio e restrições técnicas.
Processamento streaming oferece latência mínima e permite resposta em tempo real para eventos críticos, mas vem com complexidade adicional e custos de infraestrutura mais altos. Processamento batch é mais eficiente para transformação de dados de alto volume e oferece melhor previsibilidade de custos, mas introduz latência que pode não ser aceitável para casos de uso sensíveis ao tempo.
A solução desenvolvida utiliza abordagem híbrida que roteia dados através de caminhos de processamento apropriados baseado em criticidade e características de volume. Dados de alto valor e baixa latência fluem através de pipelines streaming, enquanto análise histórica em massa utiliza processamento batch otimizado.
Critérios de seleção de caminho de processamento:
Criticidade de negócio e requisitos de sensibilidade ao tempo
Volume de dados e complexidade computacional
Restrições de custo e disponibilidade de recursos

Padrões de design para escalabilidade
Projetar para escala desde o início é essencial porque volumes de dados e requisitos analíticos inevitavelmente crescem ao longo do tempo. A arquitetura implementada utiliza padrões que permitem escalonamento horizontal sem exigir reescritas importantes ou migrações de sistema.
A abordagem utiliza arquitetura de microsserviços onde componentes individuais de processamento podem escalar independentemente baseado na demanda. Estratégias de particionamento de dados garantem que carga de processamento se distribua uniformemente através de recursos disponíveis, enquanto camadas de cache reduzem computação redundante para dados frequentemente acessados.
Orquestração de contêineres permite escalonamento automático baseado na carga atual, garantindo que performance do sistema permaneça consistente mesmo durante períodos de pico de uso. Esta elasticidade é particularmente importante para cargas de trabalho de business intelligence que frequentemente exibem padrões de uso imprevisíveis.

Otimização de custos através de roteamento inteligente
Uma consideração frequentemente negligenciada no design de pipeline é otimização de custos através de roteamento inteligente de dados. Diferentes tipos de análise têm características de custo vastamente diferentes, e decisões de roteamento podem impactar significativamente despesas operacionais.
O sistema desenvolvido analisa cada solicitação de dados para determinar a abordagem de processamento mais custo-efetiva. Agregações simples utilizam resultados em cache quando disponíveis, consultas analíticas complexas são roteadas para recursos computacionais de alta performance, e análise histórica usa recursos de processamento batch de menor custo.
Este roteamento inteligente alcançou 45% de redução nos custos de processamento enquanto mantinha ou melhorava tempos de resposta para a maioria das solicitações de usuários. Um insight-chave foi que a maioria das consultas de BI pode ser atendida através de estratégias inteligentes de cache e pré-computação.
Integração com business intelligence
Arquiteturas de dashboard em tempo real
Business intelligence moderno requer dashboards que reflitam o estado atual do negócio, não instantâneos históricos que podem ter horas ou dias de atraso. Implementar capacidades de BI em tempo real requer consideração cuidadosa tanto da arquitetura técnica quanto do design da experiência do usuário.
O desafio é balancear atualizações em tempo real com performance do dashboard e compreensão do usuário. Atualizações muito frequentes podem tornar dashboards difíceis de ler, enquanto frequência insuficiente de atualização derrota o propósito das capacidades em tempo real.
A solução implementada utiliza estratégias inteligentes de atualização que refrescam métricas críticas continuamente enquanto fazem batch de atualizações menos críticas para melhorar tanto performance quanto usabilidade. Usuários podem configurar taxas de refresh baseado em suas necessidades específicas e cadência de tomada de decisão.
Habilitação de analytics self-service
Empoderar usuários de negócio para realizar suas próprias análises reduz gargalos em equipes analíticas e permite tomada de decisão mais rápida. No entanto, analytics self-service requer data pipelines que entreguem dados limpos e bem documentados em formatos que usuários de negócio possam facilmente entender e manipular.
Nossa implementação inclui catalogação automatizada de dados que descreve datasets disponíveis, seu significado de negócio, e casos de uso apropriados. Construtores de consultas interativos permitem usuários de negócio explorar dados sem exigir conhecimento de SQL, mantendo guardrails que previnem consultas inadequadas ou ineficientes.
O resultado foi 70% de redução em solicitações para equipe de analistas para relatórios básicos, liberando recursos especializados para trabalho analítico de maior valor que requer expertise de domínio.
Funcionalidades de habilitação self-service:
Descoberta automatizada de dados e catalogação
Interfaces de consulta amigáveis para negócio
Templates analíticos pré-construídos
Monitoramento de uso e sugestões de otimização
Integração de analytics avançado
Business intelligence cada vez mais incorpora machine learning e análise estatística avançada que requerem diferentes padrões de preparação e serviço de dados que relatórios tradicionais. A arquitetura do pipeline deve acomodar essas cargas de trabalho analíticas avançadas junto com requisitos convencionais de BI.
Integração com workflows de ML requer atenção cuidadosa para linhagem de dados, pipelines de engenharia de features, e infraestrutura de serving de modelos. Os mesmos dados que servem dashboards executivos devem também alimentar modelos preditivos que informam decisões operacionais.
Nossa solução cria camada unificada de serviço de dados que suporta tanto ferramentas tradicionais de BI quanto plataformas avançadas de analytics, garantindo consistência através de diferentes abordagens analíticas enquanto otimiza performance para cada caso de uso.
Governança e compliance
Linhagem de dados e trilhas de auditoria
Compliance regulatório e governança de negócio requerem rastreamento consistente de como dados fluem através de sistemas analíticos. Entender onde dados se originaram, como foram transformados, e quem os acessou é crítico para manter confiança e atender requisitos de compliance.
A arquitetura de pipeline implementada rastreia automaticamente linhagem completa de dados desde sistemas de origem através de todas as etapas de transformação até saídas analíticas finais. Esta informação de linhagem é acessível através de interfaces amigáveis ao usuário que permitem tanto equipe técnica quanto stakeholders de negócio entender proveniência dos dados.
Trilhas de auditoria capturam não apenas movimento de dados mas também padrões de uso analítico, permitindo organizações demonstrar compliance com regulações de privacidade e políticas internas de governança.
Considerações de privacidade e segurança
Pipelines de business intelligence lidam com dados organizacionais sensíveis que requerem proteção através de múltiplas camadas de segurança. Segurança deve ser integrada no design do pipeline desde o início, não adicionada como reflexão tardia.
A abordagem de segurança implementada inclui criptografia em repouso e em trânsito, controles de acesso baseados em função que aplicam políticas de governança de dados de negócio, e técnicas de mascaramento de dados que protegem informações sensíveis em ambientes de não-produção.
Framework de segurança multi-camada:
Controles de acesso baseados em identidade com permissões granulares
Criptografia de dados através de todas as etapas do pipeline
Detecção e proteção automatizada de dados sensíveis
Auditorias regulares de segurança e avaliações de vulnerabilidade
Retenção de dados e gestão de ciclo de vida
Sistemas de business intelligence acumulam vastas quantidades de dados históricos, criando desafios para custos de armazenamento, performance de consultas, e compliance com políticas de retenção de dados. Gestão inteligente de ciclo de vida de dados é essencial para manter eficiência do sistema e compliance regulatório.
Nossa implementação arquiva automaticamente dados mais antigos para armazenamento de menor custo mantendo capacidades de consulta através de estratégias de armazenamento em camadas. Políticas de retenção de dados são aplicadas automaticamente baseado em requisitos de negócio e mandatos regulatórios.
O sistema também fornece capacidades para compliance com direito ao esquecimento, permitindo remoção de registros individuais sem impactar capacidades analíticas mais amplas.
Otimização de performance
Estratégias de otimização de consultas
Cargas de trabalho de business intelligence frequentemente envolvem consultas complexas através de grandes datasets, tornando otimização de consultas crítica para experiência do usuário e escalabilidade do sistema. Técnicas tradicionais de otimização de banco de dados devem ser adaptadas para cargas de trabalho analíticas modernas que podem envolver streams de dados em tempo real e fontes de dados diversas.
A abordagem de otimização desenvolvida utiliza estratégias inteligentes de indexação que se adaptam para padrões de consulta, views materializadas que pré-computam agregações frequentemente solicitadas, e cache de resultados de consulta que reduz computação redundante.
Particularmente eficaz foi implementar otimização adaptiva que aprende de padrões de consulta do usuário e automaticamente ajusta estratégias de indexação e cache para melhorar performance ao longo do tempo. Esta abordagem alcançou 60% de melhoria nos tempos médios de resposta de consultas.
Alocação de recursos e gestão de workload
Cargas de trabalho analíticas são inerentemente imprevisíveis, com padrões de uso que variam dramaticamente baseado em ciclos de negócio, eventos organizacionais, e fatores externos. Gestão eficaz de recursos requer sistemas que podem se adaptar para demanda em mudança mantendo eficiência de custos.
Nossa solução implementa classificação de workload que automaticamente prioriza consultas baseado em importância de negócio e papéis de usuários. Consultas de dashboard executivo recebem prioridade mais alta que análise exploratória, garantindo que informação crítica de negócio permaneça disponível mesmo durante períodos de pico de uso.
Técnicas de gestão de workload implementadas:
Alocação dinâmica de recursos baseada em prioridade de consulta
Otimização automática de enfileiramento e agendamento de consultas
Monitoramento de recursos com escalonamento proativo
Otimização de consultas baseada em custo que balanceia performance com despesas
Estratégias de cache para workloads de BI
Cache inteligente é talvez a otimização mais impactante para sistemas de business intelligence. Consultas de BI frequentemente exibem padrões que tornam cache altamente eficaz, mas implementar cache requer compreensão de contexto de negócio e padrões de comportamento do usuário.
A estratégia de cache desenvolvida opera em múltiplas camadas, desde cache de resultados para consultas frequentemente idênticas até pré-computação inteligente de prováveis consultas futuras baseado em análise de comportamento do usuário.
Particularmente inovador foi implementar invalidação de cache consciente de negócio que entende quando mudanças de dados subjacentes afetam resultados em cache, garantindo que usuários sempre recebam informação precisa enquanto maximizam taxas de acerto de cache.
Medindo sucesso e impacto no negócio
Métricas quantitativas de performance
Medir sucesso de implementações de data pipeline requer métricas que capturem tanto performance técnica quanto valor de negócio. Métricas técnicas tradicionais como throughput e latência são importantes mas insuficientes para demonstrar impacto no negócio.
O framework de mensuração desenvolvido rastreia métricas técnicas junto com indicadores orientados a negócio como time-to-insight, velocidade de tomada de decisão, e taxas de auto-suficiência analítica. Estas métricas combinadas fornecem visão abrangente da eficácia do sistema.
Indicadores-chave de performance rastreados:
Latência de processamento de dados desde origem até consumo de BI
Tempos de resposta de consultas através de diferentes personas de usuário
Métricas de qualidade de dados incluindo precisão e completude
Taxas de adoção de usuário para capacidades analíticas self-service
Custo por insight analítico entregue
Avaliação de valor de negócio
Quantificar valor de negócio de data pipelines melhorados requer conectar melhorias técnicas para resultados mensuráveis de negócio. Esta avaliação deve considerar tanto benefícios diretos como redução de custos quanto benefícios indiretos como qualidade melhorada de tomada de decisão.
Para a empresa parceira, benefícios incluíram resposta mais rápida para oportunidades de mercado devido ao time-to-insight reduzido, precisão melhorada de previsão através de melhor qualidade de dados, e produtividade aumentada de analistas através de overhead reduzido de preparação de dados.
O framework de avaliação também considera benefícios estratégicos como posicionamento competitivo aprimorado através de tomada de decisão orientada por dados e experiência melhorada do cliente através de melhor compreensão de padrões de comportamento do cliente.
Metodologias de cálculo de ROI
Calcular ROI para investimentos em data pipeline envolve desafios porque benefícios frequentemente se acumulam através de múltiplas funções de negócio e podem ser difíceis de isolar de outras iniciativas de melhoria. Avaliação abrangente de ROI requer metodologias sofisticadas de atribuição.
Nossa abordagem rastreia tanto economias diretas de custos quanto melhorias de eficiência operacional, quantifica ganhos de produtividade através de estudos de tempo e movimento, e estima valor estratégico através de modelagem de impacto no negócio.
A análise mostrou 340% de ROI ao longo de 24 meses (extrapolação a partir dos resultados de 8 meses), impulsionado principalmente por melhorias de produtividade, velocidade melhorada de tomada de decisão, e capacidades analíticas aprimoradas que permitiram novas oportunidades de negócio.
Evolução futura e padrões emergentes
Integração de ML em tempo real
A fronteira entre business intelligence e machine learning continua a se desfocar conforme organizações buscam incorporar insights preditivos em tomada de decisão operacional. Arquiteturas futuras de pipeline devem suportar perfeitamente tanto cargas de trabalho tradicionais de BI quanto inferência de ML em tempo real.
Esta integração requer designs de pipeline que podem servir tanto consultas analíticas históricas quanto extração de features em tempo real para modelos de ML, mantendo consistência e qualidade de dados através de ambos os casos de uso.
Nosso roadmap inclui implementação de camada unificada de serving que suporta tanto ferramentas de BI quanto inferência de modelos de Machine Learning, permitindo organizações moverem perfeitamente entre analytics descritivo e insights preditivos.
Edge analytics e processamento distribuído
Conforme organizações se tornam mais distribuídas e fontes de dados se multiplicam, capacidades de edge analytics tornam-se cada vez mais importantes para reduzir latência e custos de largura de banda enquanto habilitam tomada de decisão local.
Arquiteturas futuras de pipeline devem suportar processamento distribuído que pode lidar com cargas de trabalho analíticas locais mantendo governança e coordenação centralizadas. Esta abordagem híbrida permite tanto insights organizacionais globais quanto otimização operacional local.
Geração automatizada de insights
Arquiteturas avançadas de pipeline cada vez mais incorporam detecção automatizada de insights que pode identificar padrões interessantes, anomalias, ou tendências sem consultas explícitas do usuário. Estas capacidades transformam business intelligence de relatórios passivos para entrega proativa de insights.
Implementação dessas capacidades requer algoritmos analíticos sofisticados que entendem contexto de negócio e podem distinguir entre padrões significativos e ruído estatístico. O objetivo é obter insights acionáveis que poderiam ser perdidos através de abordagens analíticas tradicionais.
Conclusão: Data pipelines como habilitador estratégico
Data pipelines eficazes representam muito mais que infraestrutura técnica - são habilitadores estratégicos que fundamentalmente transformam como organizações entendem e respondem para desafios de negócio. Quando projetados cuidadosamente, criam vantagens competitivas através de velocidade, precisão e abrangência superiores de tomada de decisão.
As lições mais importantes que aprendi através de implementar arquiteturas modernas de data pipeline centram-se em tratar pipelines como sistemas críticos de negócio que requerem a mesma atenção para confiabilidade, segurança, e performance como aplicações voltadas para o cliente.
Para CTOs considerando modernização de data pipeline: comece com compreensão clara dos processos de tomada de decisão de negócio que você quer habilitar, projete para escala e flexibilidade desde o primeiro dia, e invista em monitoramento abrangente que rastreia tanto performance técnica quanto entrega de valor de negócio.
O futuro pertence para organizações que podem efetivamente transformar dados brutos em insights acionáveis através de arquiteturas robustas e escaláveis de pipeline. Os frameworks técnicos e estratégias de negócio delineados aqui fornecem base para construir capacidades de dados que criam vantagem competitiva duradoura através de inteligência organizacional superior.
Sucesso no negócio moderno cada vez mais depende da capacidade de tomar decisões mais rápidas e mais precisas que concorrentes. Data pipelines bem projetados são infraestrutura essencial para alcançar esta capacidade, transformando organizações de reativas para proativas através de insights orientados por dados que informam todos os aspectos das operações de negócio.
Continue acompanhando para mais insights sobre como implementar arquiteturas modernas que transformam dados em vantagem competitiva através de soluções de business intelligence que realmente escalam e entregam valor.


