

Quanta memória GPU é necessária para rodar um grande modelo de linguagem LLM?

Em quase todas as conversas de LLM que tenho, há uma pergunta que surge consistentemente: “Quanta memória GPU é necessária para rodar um Large Language Model (LLM)?”
Esta não é apenas uma pergunta aleatória – é um indicador importante de quão bem você entende a implantação e a escalabilidade desses modelos poderosos em produção.
Ao trabalhar com modelos como GPT, LLaMA, Claude ou qualquer outro LLMs, é essencial entender como estimar a memória GPU necessária. Esteja você lidando com um modelo de parâmetro 7B ou algo significativamente maior, dimensionar corretamente o hardware para atender a esses modelos é fundamental.
Vamos mergulhar na matemática que o ajudará a estimar a memória da GPU necessária para implantar esses modelos de maneira eficaz.
Para mais informações sobre o papel das GPUs nos LLMs, acesse aqui.
A fórmula para estimar a memória da GPU
Para estimar a memória da GPU necessária para servir um modelo de linguagem grande, você pode usar a seguinte fórmula:
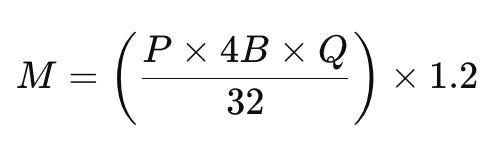
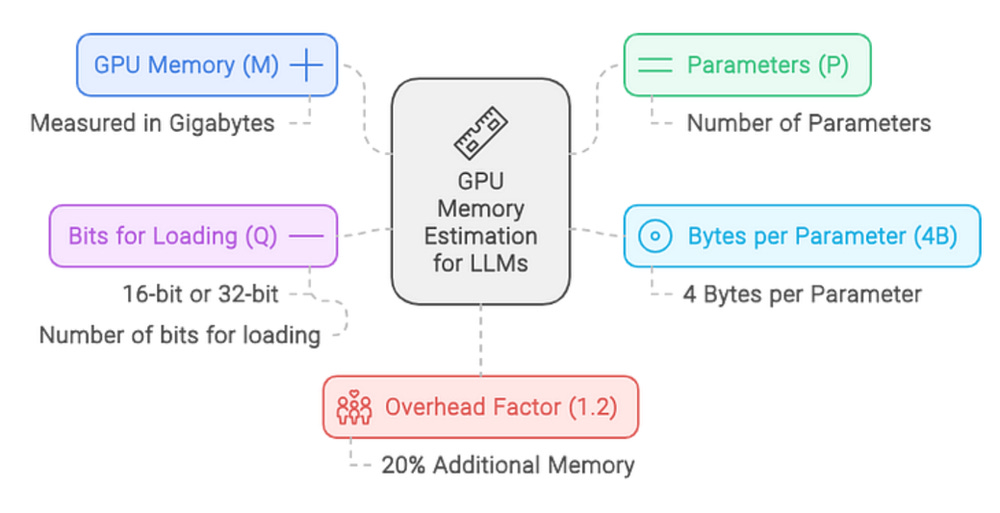
M é a memória da GPU em Gigabytes.
P é o número de parâmetros no modelo.
4B representa os 4 bytes usados por parâmetro.
P é o número de bits para carregar o modelo (por exemplo, 16 bits ou 32 bits).
Q representa bits por parâmetro
1.2 representa uma sobrecarga de 20%.
Quebrando a fórmula
Número de parâmetros (P):
Isso representa o tamanho do seu modelo. Por exemplo, se você estiver trabalhando com um modelo LLaMA que possui 70 bilhões de parâmetros (70B), esse valor seria 70 bilhões.
Bytes por parâmetro (4B):
Cada parâmetro normalmente requer 4 bytes de memória. Isso ocorre porque a precisão do ponto flutuante geralmente ocupa 4 bytes (32 bits). No entanto, se você estiver usando meia precisão (16 bits), o cálculo será ajustado de acordo.
Bits por parâmetro (Q):
Dependendo se você está carregando o modelo com precisão de 16 ou 32 bits, esse valor mudará. A precisão de 16 bits é comum em muitas implantações de LLM, pois reduz o uso de memória enquanto mantém precisão suficiente.
Despesas gerais (1.2):
O multiplicador 1,2 adiciona uma sobrecarga de 20% para compensar a memória adicional usada durante a inferência. Este não é apenas um buffer de segurança; é crucial para cobrir a memória necessária para ativações e outros resultados intermediários durante a execução do modelo.
Exemplo de cálculo
Vamos considerar que você deseja estimar a memória necessária para servir um modelo LLaMA com 70 bilhões de parâmetros, carregado com precisão de 16 bits:
Dados:
P = 70 bilhões de parâmetros =
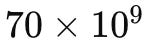
B = 4 bytes por parâmetro
Q = 16 bits por parâmetro
Overhead = 1.2 (20% de sobrecarga)
Passo a Passo:
1. Calcular o número total de bytes para armazenar os parâmetros do modelo:
A fórmula é: P × B × Q
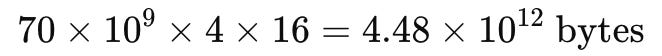
2. Dividir por 32 para ajustar para bits por parâmetro:
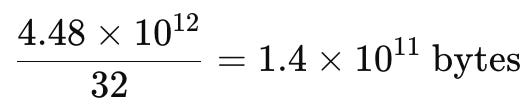
3. Aplicar a sobrecarga de 20% (multiplicar por 1.2):
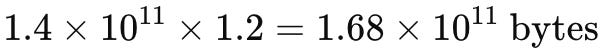
4. Converter bytes para Gigabytes:
Lembrando que:
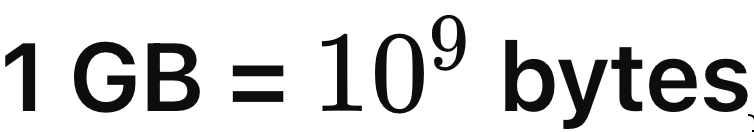
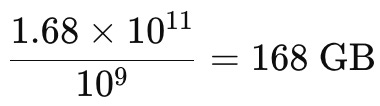
A memória necessária para servir um modelo LLaMA com 70 bilhões de parâmetros, carregado com precisão de 16 bits, é de aproximadamente 168 GB.
Caso queira fazer o cálculo usando um notebook Jupiter ou utilizando Python, use o seguinte código:
Abra este código no colab do Google: https://colab.research.google.com/drive/1R6kuyA8rt293TfcryyWZT71VJQKpcldI?usp=sharing
Ao dominar esse cálculo, você estará preparado para responder a essa pergunta essencial e, mais importante, evitar gargalos de hardware dispendiosos em suas implantações e suas inovações.
Otimização de Memória para LLMs em GPUs
A gestão eficiente da memória GPU tornou-se um desafio crucial para desenvolvedores e pesquisadores. Um aspecto fundamental dessa otimização envolve a escolha da precisão numérica utilizada nos cálculos do modelo.
Precisão de 16 bits vs. 32 bits
Tabela comparativa quanto à otimização de memória para LLMs em GPUs: 16 bits vs 32 bits
Considerações para Implantação
A escolha entre precisão de 16 bits e 32 bits não é universal e depende de vários fatores:
Requisitos de Precisão: Avalie se a ligeira perda de precisão com 16 bits é aceitável para sua aplicação.
Recursos de Hardware: Considere a memória GPU disponível e a arquitetura das GPUs utilizadas.
Escala do Modelo: Modelos maiores podem se beneficiar mais da redução de memória oferecida pelos 16 bits.
Fase do Projeto: A precisão de 16 bits pode ser mais adequada para inferência, enquanto 32 bits pode ser preferível durante o treinamento.
Implicações Práticas
Compreender e aplicar esta fórmula e o cálculo não é apenas teórico; tem implicações no mundo real. Por exemplo, uma única GPU NVIDIA A100 com 80 GB de memória não seria suficiente para atender este modelo. Você precisaria de pelo menos duas GPUs A100 com 80 GB cada para lidar com a carga de memória com eficiência.
E em que isso implica?
Escalabilidade do Modelo: Este exemplo mostra como os modelos de linguagem de última geração estão ultrapassando as capacidades de hardware individual, mesmo considerando GPUs de alto desempenho como a A100.
Necessidade de Paralelismo: Para modelos extremamente grandes, como o LLaMA de 70B, o uso de múltiplas GPUs torna-se não apenas uma opção de otimização, mas uma necessidade.
Importância da Precisão Reduzida: O uso de precisão de 16 bits é crucial para tornar viável a execução desses modelos gigantes. Sem essa redução, os requisitos de memória seriam ainda maiores.
Custo e Infraestrutura: A necessidade de múltiplas GPUs de alta performance implica em consideráveis investimentos em hardware e infraestrutura de computação.
Desafios de Engenharia: Distribuir eficientemente um modelo tão grande entre múltiplas GPUs apresenta desafios significativos de engenharia de software e otimização de performance.
Mas isso tudo é tema de outro post.